Cuando empezamos a trabajar con Pandas y Python, una de las principales operaciones que hay que aprender es la selección de filas de un DataFrame que cumplan un determinado criterio. Por ejemplo:
- Necesito obtener todos los asistentes a un congreso que tengan menos de 35 años.
- Necesito el listado de clientes que se hayan registrado antes del 23 de marzo de un determinado año.
- Necesito obtener aquellos empleados que trabajen el departamento de atención al cliente y que tengan una antigüedad de menos de tres meses.
Bueno, creo que vas entendiendo la idea. Se trata de filtrar un DataFrame para obtener aquellas filas en las que los valores de sus columnas cumplan una o varias condiciones.
Para seleccionar filas de un DataFrame de Pandas en Python se puede utilizar la propiedad loc indicando entre los corchetes las condiciones a cumplir por los valores de sus columnas, por ejemplo: df.loc[dt[columna]==valor]. Alternativamente se puede usar la función query.
Te cuento aquí la teoría y algunos ejemplos. Si no te interesa la teoría y necesitas ver de manera rápida cómo realizar una selección de filas salta directamente a la sección de ejemplos.
Seleccionar filas de un DataFrame con la propiedad loc
La propiedad loc nos permite obtener un conjunto de filas de un DataFrame por su etiqueta o mediante un array de booleanos. En este caso, lo que nos interesa es la segunda opción.
El funcionamiento es muy sencillo. Si proporcionamos a la propiedad loc de un DataFrame un array con tantos valores booleanos como filas tiene el DataFrame, nos devolverá solo aquellas filas en las que el array tiene el valor True.
Dicho de otra manera, si tenemos un DataFrame con 3 filas, por ejemplo fila_1, fila_2 y fila_3 y le proporcionamos a loc el array True, False, True el resultado será obtener un nuevo DataFrame con las filas fila_1 y fila_3. ¿Sencillo, no?
Sabiendo esto el problema se reduce a generar ese array de booleanos, poniendo True en aquellas filas que nos interesan y False en las que no queremos.
Para ello podemos hacer uso de la notación de corchetes de un DataFrame para acceder a las columnas y de un conjunto de comparadores y operadores booleanos.

Uno de los mejores libros sobre Pandas y el análisis de datos en Python
De la mano del propio creador de Pandas, Wes McKinney.
Operadores booleanos en Pandas
En Pandas podemos comparar los valores de una columna con los siguientes operadores, que casi no necesitan explicación si dominas las condicionales en Python:
- Comparación de igualdad. Comprobamos si el valor de una columna es igual a otro:
==. - Comparación de no igualdad. Comprobamos si el valor de una columna es diferente a otro:
!=. - Comparaciones de menor que, menor o igual que, mayor que y mayor o igual que:
<,<=,>,>=. - Comprobación de pertenencia a un conjunto. Función
isinque recibe una colección de elementos y comprueba si el valor de la columna se encuentra dentro de ellos.
Cualquiera de estos operadores se puede negar para realizar la comprobación opuesta o contraria anteponiendo el operador ~ a la condición.
Estos comparadores y la negación se pueden combinar creando condiciones múltiples con los siguientes operadores y agrupando con paréntesis según sea necesario:
- Operador and: combinamos dos condiciones que debe ser
Truepara obtenerTrueen toda la expresión. El símbolo del operador es&. - Operador or: combinamos dos condiciones en las que al menos una de ellas debe ser
Truepara obtenerTrueen toda la expresión. El operador es|.
¡Cuidado! Los operadores ~, & y | tienen menor precedencia que que los comparadores vistos previamente, al revés que sucede con las condiciones de Python. Es por ello que es necesario utilizar paréntesis para agrupar las expresiones y tener los resultados deseados.
Pero, ¡ya basta de tanta teoría! Vamos a ver ejemplos, que es lo interesante.
Ejemplos
Vamos a suponer que tenemos un DataFrame con los datos de los empleados de una pequeña empresa. Para cada empleado tendremos su nombre, edad, departamento de la empresa al que pertenece y el número de trienios de antigüedad. Los datos son los siguientes:
Nombre Edad Departamento Trienios 0 Pepe 39 Comunicación 1 1 Antonio 43 Administración 0 2 Marco 37 Ventas 3 3 Juan 43 Dirección 4 4 Laura 42 Administración 5
Para cargar estos datos en un DataFrame vamos a hacerlo de manera rápida creándolo a partir de un diccionario, creando un elemento en un diccionario para cada columna donde la clave es el nombre de la columna y el valor una con los elementos de dicha columna:
Te envío todos los días un consejo para que cada día seas mejor en Python.
Siempre sobre Python y programación.
Más de 2500 personas como tú los reciben cada día.
Día que estás fuera, consejo sobre Python que te pierdes.
Antes de suscribirte consulta aquí la
Finalidad de recogida y tratamiento de datos personales: enviarte boletín informativo de Python y comunicaciones comerciales.
Legitimación: tu consentimiento.
Destinatarios: no se ceden a terceros. Los datos se almacenan en los servidores de marketing (GetResponse).
Derechos: podrás ejercer tus derechos de acceso, rectificación, limitación y supresión de datos en info @ codigopiton.com así como presentar una reclamación ante una autoridad de control.
Más información: política de privacidad, encontrarás información adicional sobre la recopilación y el uso de tu información personal.
import pandas as pd
datos = {
'Nombre' : ['Pepe', 'Antonio', 'Marco', 'Juan', 'Laura'],
'Edad': [39, 43, 37, 43, 42],
'Departamento': ['Comunicación', 'Administración', 'Ventas', 'Dirección', 'Administración'],
'Trienios': [1, 0, 3, 4, 5]
}
empleados = pd.DataFrame(datos)Si tienes tus datos en otro formato o fichero, aquí te explico cómo crear un DataFrame de Pandas de muchas formas diferentes.
Empecemos con algo sencillo y directo. Vamos a obtener los empleados que se llaman Juan. Para crear el array de booleanos basta con comparar la columna con el valor que nos interesa:
array_booleanos = empleados['Nombre'] == 'Juan'
print(array_booleanos)Y obtendremos lo siguiente:
0 False 1 False 2 False 3 True 4 False
Si te fijas, es justo la cuarta fila (la de índice 3) la que contiene un True mientras que las demás están a False, que es justamente la fila que corresponde con el empleado Juan. Dándole este array a la propiedad loc obtendremos exactamente la fila que nos corresponde.
No hace falta utilizar la variable array_booleanos podemos indicar la expresión directamente como índice entre los corchetes de loc:
juan = empleados.loc[empleados['Nombre'] == 'Juan']
print(juan)El resultado será:
Nombre Edad Departamento Trienios 3 Juan 43 Dirección 4
Ya ves que es bastante directo y sencillo. Veamos otros ejemplos.
Ahora necesito todos los empleados que no sean Juan. Tenemos dos maneras de hacerlo: utilizando el comparador != o la negación ~ junto con el comparador ==.
resto = empleados.loc[empleados['Nombre'] != 'Juan'] # alternativa 1
resto = empleados.loc[~(empleados['Nombre'] == 'Juan')] # alternativa 2Ya te puedes imaginar el resultado. Vamos a obtener los empleados menores de 40 años. Esta vez usamos el operador < con la columna Edad:
menos_40 = empleados.loc[empleados['Edad'] < 40]Y el resultado es:
Nombre Edad Departamento Trienios 0 Pepe 39 Comunicación 1 2 Marco 37 Ventas 3
Pasamos a crear condiciones más complejas y obtenemos los empleados que trabajen en el departamento de administración o aquellos que tengan más de 2 trienios. Usamos el operador |:
adm_trienios_2 = empleados.loc[(empleados['Departamento'] == 'Administración') | (empleados['Trienios'] >= 2)]Obtengamos ahora aquellos empleados que no trabajen en el departamento de ventas y que tengan menos de 43 años. Usamos el operador &:
no_ventas_43 = empleados.loc[(empleados['Departamento'] != 'Ventas') & (empleados['Edad'] < 43)]Y ahora, un ejemplo utilizando el operador isin, con el que comprobamos que el valor de una columna está dentro de un conjunto de valores. Vamos a obtener los empleados que tengan 39 o 43 años. Podemos pasar los valores a isin en un conjunto, una lista o una tupla :
edad_39_43 = empleados.loc[empleados['Edad'].isin((39, 43))]Y tendremos de resultado:
Nombre Edad Departamento Trienios 0 Pepe 39 Comunicación 1 1 Antonio 43 Administración 0 3 Juan 43 Dirección 4
Bueno, creo que son suficientes ejemplos. Veamos ahora algunas alternativas de notación que hacen el código algo más legible.
Notación abreviada de conveniencia
Un pequeño problema con lo que hemos visto hasta ahora con la propiedad loc es que toda la expresión queda un poco fea. Pandas nos proporciona una manera abreviada de realizar estas operaciones en la que podemos ahorrarnos el loc.
Así, podremos escribir las expresiones de la siguiente forma, que resulta un poco más limpia, y que arroja exactamente los mismos resultados:
juan = empleados[empleados['Nombre'] == 'Juan']
resto = empleados[empleados['Nombre'] != 'Juan']
menos_40 = empleados[empleados['Edad'] < 40]
adm_trienios_2 = empleados[(empleados['Departamento'] == 'Administración') | (empleados['Trienios'] >= 2)]
no_ventas_43 = empleados[(empleados['Departamento'] != 'Ventas') & (empleados['Edad'] < 43)]
edad_39_43 = empleados[empleados['Edad'].isin((39, 43))]Como ves, la propiedad loc no aparece por ningún lado.
15 conceptos fundamentales que necesitas conocer para aprender y dominar Python
Te voy a hacer cuatro regalos (no uno, no dos, no tres, cuatro) que hablan de estos 15 conceptos fundamentales de Python: mi Tutorial Básico Interactivo de Python, una cheat sheet de Python en español: La Hoja de Referencia de Python, una guía de ChatGPT y Python y 30 ejercicios de Python (es un reto para ti).
Estos regalos son exclusivos para los suscriptores de Código Pitón.
Aunque esto no está documentado oficialmente (al menos yo no lo he encontrado en la fecha de escribir este artículo), el creador de Pandas, Wes McKinney, dice en su magnífico libro Python for Data Analysis que la notación df[val] se puede usar para seleccionar una columna o una secuencia de ellas de un DaraFrame, siendo casos especiales de conveniencia los siguientes: array de booleanos (filtrado de filas), porciones o DataFrame de booleanos (con valores basados en algún criterio).
Notación de acceso a columnas por nombre de atributo
Si el nombre de la columna de un DataFrame es un nombre válido para un identificador de Python y además no coincide con el nombre de las palabras reservadas index, major_axis, minor_axis, items y tampoco coincide con el nombre de un método de la clase DataFrame, se puede acceder a dicha columna de la siguiente manera: df.nombre_columna.
Como ves, esto puede resultar más cómodo que escribir df[nombre_columna].
Así, todos los ejemplos que hemos visto antes se puede reescribir de la siguiente manera:
juan = empleados[empleados.Nombre == 'Juan']
resto = empleados[empleados.Nombre != 'Juan']
menos_40 = empleados[empleados.Edad < 40]
adm_trienios_2 = empleados[(empleados.Departamento == 'Administración') | (empleados.Trienios >= 2)]
no_ventas_43 = empleados[(empleados.Departamento != 'Ventas') & (empleados.Edad < 43)]
edad_39_43 = empleados[empleados.Edad.isin((39, 43))]Pasamos a ver una forma diferente de hacer la selección de filas.
Seleccionar filas de un DataFrame con la función query
Otra opción similar para la selección de filas basada en los valores de las columnas consiste en el uso de la función query de la clase DataFrame.
Esta función nos permite indicar el criterio para seleccionar las filas de una manera parecida, salvando las distancias, a cómo se hace en SQL (Structured Query Language) en la cláusula WHERE.
Así, a query le proporcionaremos como parámetro un string o cadena de texto con las condiciones que necesitamos que se cumplan utilizando solo los operadores vistos hasta ahora y los nombres de las columnas.
Por ejemplo, si queremos obtener el usuario llamado Juan basta con indicar 'Nombre == "Juan"'. Lo probamos:
juan = empleados.query('Nombre == "Juan"')
print(juan)El resultado será el esperado:
Nombre Edad Departamento Trienios 3 Juan 43 Dirección 4
Vamos a ver el resto de ejemplos que ya hemos visto previamente, pero con la función query. Fíjate que en este caso, los operadores ~, & y | vuelven a tener precedencia sobre los comparadores, así que podemos ahorrarnos los paréntesis:
resto = empleados.query('Nombre != "Juan"')
menos_40 = empleados.query('Edad < 40')
adm_trienios_2 = empleados.query('Departamento == "Administración" | Trienios >= 2')
no_ventas_43 = empleados.query('Departamento != "Ventas" & Edad < 43')
edad_39_43 = empleados.query('Edad in (39, 43)')Si te fijas, las expresiones son ahora más cortas y fáciles de leer. Hay que tener en cuenta que es necesario utilizar comillas en las constantes de texto.
Si necesitas utilizar en el parámetro de query el valor de alguna variable, puedes hacer uso de los f-strings. De todas maneras, Pandas proporciona una manera más cómoda de sustituir el valor de una variable en la consulta y es mediante el uso del símbolo @ y se realiza de esta manera:
nombre = 'Juan'
juan = empleados.query('Nombre == @nombre')Hasta aquí ya tenemos las dos alternativas que quería presentarte: loc (y sus variantes) y query. Tendrás que decantarte por alguna. Sigue leyendo...
Estudio de rendimiento
Bueno, pues hemos visto varias opciones para hacer la selección de filas. ¿Cuál utilizamos?
Si estamos trabajando con conjuntos de datos pequeños, con pocas operaciones o en proyectos donde la eficiencia temporal no es relevante, podemos utilizar la que más nos guste o la que más se adapte a nuestro estilo de programación y al proyecto en cuestión.
Pero, ¿qué pasa cuando trabajamos con conjuntos grandes o tenemos que prestar especial atención a la eficiencia?
En este caso cambia la cosa, porque, internamente, Pandas funciona diferente al usar loc o query.
Día que estás fuera, consejo sobre Python que te pierdes.
Antes de suscribirte consulta aquí la
Finalidad de recogida y tratamiento de datos personales: enviarte boletín informativo de Python y comunicaciones comerciales.
Legitimación: tu consentimiento.
Destinatarios: no se ceden a terceros. Los datos se almacenan en los servidores de marketing (GetResponse).
Derechos: podrás ejercer tus derechos de acceso, rectificación, limitación y supresión de datos en info @ codigopiton.com así como presentar una reclamación ante una autoridad de control.
Más información: política de privacidad, encontrarás información adicional sobre la recopilación y el uso de tu información personal.
He realizado un pequeño estudio de rendimiento para ver qué efecto tiene el uso de una u otra técnica en el tiempo de ejecución.
Para ello, he creado varios DataFrame de cuatro columnas. Tres de las columnas son de números aleatorios entre 0 y 1 (columnas A, B y C) y la cuarta es una cadena de texto (columna T) con el siguiente formato tN donde N es un numero aleatorio entre 100, 200, 300, 400 y 500. El tamaño de los DataFrame varía entre las 10000 y las 50000 filas.
He definido un criterio de selección que es el siguiente: obtener las filas cuya suma de valores de las columnas A y B sea superior que el de la columna C y cuya columna T sea diferente de t300. He creado dos funciones para aplicar la selección, una con la versión loc y otra con query. El código es el siguiente:
def seleccion_loc(df):
return df.loc[(df['A'] + df['B'] > df['C']) & (df['T'] != 't300')]
def seleccion_query(df):
return df.query('A + B > C & T != "t300"')El siguiente paso fue llamar a cada una de estas funciones con cada uno de los DataFrame generados de distintos tamaños. Se realizaron 1000 ejecuciones para cada combinación de criterio y DataFrame (con la ayuda de la librería timeit).
El resultado se puede ver en el siguiente gráfico, donde se aprecia que, para DataFrames de más de 30000 filas (aproximadamente) resulta más eficiente la versión query, mientras que para los que son más pequeños, lo mejor es optar por la versión loc.
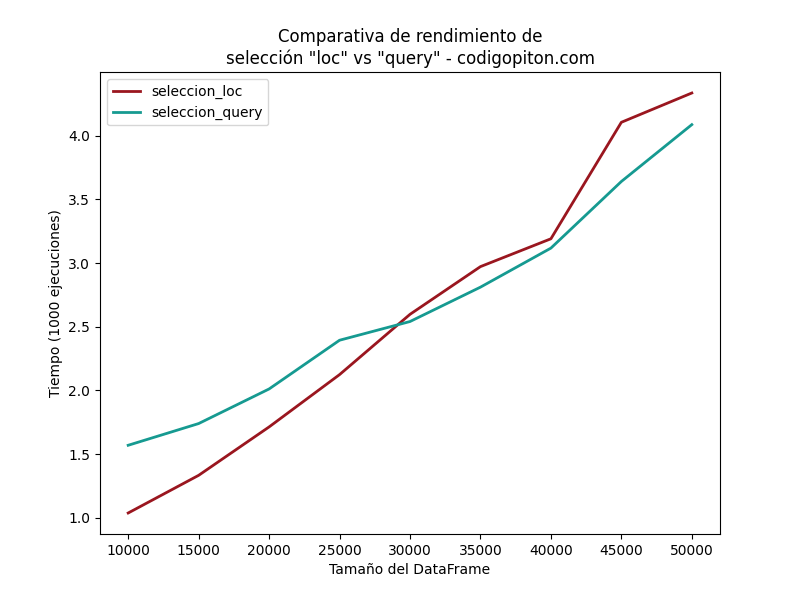
de distintos tamaños utilizando
loc y queryEsta es una pequeña prueba, es posible que si la realizas tú obtengas resultados diferentes. Además, es muy dependiente del criterio que utilicemos. Cuanto más complejo sea este más tiempo se necesitará para hacer el filtrado. También depende de la estructura y los tipos de datos del DataFrame. Es decir, que hay muchas variables, así que recuerda hacer tu propio estudio y decide la mejor alternativa en función de tu proyecto.
Conclusiones
Espero que con este artículo hayas aprendido la manera de hacer la selección de filas de un DataFrame a partir de criterios basados en el valor de las columnas.
Hemos visto dos alternativas:
- Con
loc. Con sus tres variantes equivalentes:df.loc[df[columna]==valor]df[df[columna]==valor]df[df.columna==valor]
- Con
query:df.query('columna==valor')
Sea cual sea la opción que uses puedes utilizar los operadores de negación ~, de and & y de or |, así como los paréntesis
Ten en cuenta que el rendimiento de ambas opciones es diferente. query tiende a comportarse mejor que loc en DataFrames muy grandes.
Aunque no lo hemos visto en los ejemplos, puedes realizar operaciones matemáticas entre los valores de las columnas para crear criterios de selección complejos. Puedes ver un ejemplo en la sección de estudio de rendimiento.
Echa un ojo al libro Python for Data Analysis del creador de Python Wes McKinney. El libro está en inglés y lamentablemente no hay de momento una traducción al español.
¡Feliz programación!
Te envío todos los días un consejo para que cada día seas mejor en Python.
Siempre sobre Python y programación.
Más de 2500 personas como tú los reciben cada día.
Día que estás fuera, consejo sobre Python que te pierdes.
Antes de suscribirte consulta aquí la
Finalidad de recogida y tratamiento de datos personales: enviarte boletín informativo de Python y comunicaciones comerciales.
Legitimación: tu consentimiento.
Destinatarios: no se ceden a terceros. Los datos se almacenan en los servidores de marketing (GetResponse).
Derechos: podrás ejercer tus derechos de acceso, rectificación, limitación y supresión de datos en info @ codigopiton.com así como presentar una reclamación ante una autoridad de control.
Más información: política de privacidad, encontrarás información adicional sobre la recopilación y el uso de tu información personal.