Si DataFrame es el tipo de datos fundamental de la librería pandas, está claro que la habilidad principal que debemos tener con esta librería es la manera de crear un DataFrame a partir de datos.
El problema principal es que los datos de origen suelen venir en muy variadas formas, ya sea en una lista, un diccionario, un array de NumPy, un fichero de texto plano, un fichero CSV (valores separados por comas), un fichero JSON, una base de datos, etc. Te cuento en este artículo cómo crear un DataFrame desde cualquier fuente de datos.
Para crear un DataFrame se usa la función constructora DataFrame() a la que se le proporciona una lista o diccionario con los datos a introducir. Si los datos se encuentran en un fichero o base de datos se deben usar las funciones propias como read_csv, read_excel, read_json, read_html o read_sql.
Antes de seguir... ¿Encuentras aquí lo que buscas? ¿Es de ayuda esta página? Suscríbete gratis a mi lista de correo para recibir consejos de Python y un montón de regalos suculentos --> Más información aquí.
Sigue leyendo para tener una idea general de cómo generar un DataFrame a partir de cualquier fuente de datos. Te voy contando de una en una y poniéndote ejemplos para que te quede muy claro. O busca en la tabla de contenidos aquella en la que tienes interés o la que necesites para tu proyecto.
Si te gusta este contenido, considera suscribirte a la lista de correo de Código Pitón y obtendrás de manera gratuita la Hoja de Referencia de Python que te permitirá agilizar tu aprendizaje, además de recibir consejos de programación, trucos y novedades.
¡Alto! ¿Necesitas que alguien te ayude con Pandas? ¿Quieres que alguien lo haga por ti?
Puedes contratar (a un precio muy, muy económico) a un programador de Python y Pandas en Fiverr.
Te recomiendo a estos dos (ambos hablan español), que están especializados en Pandas a los que podrás pedirles lo que necesites:
- Abdelmoulaelbou (Análisis de datos utilizando Python y Pandas)
- Carlosswanton (Análisis y visualización de datos con Python y Pandas)
Solo tienes que registrarte en Fiverr y contratarlos, ¡es muy sencillo! (links de afiliado de Fiverr). Yo mismo he usado Fiverr en diversas ocasiones y es una plataforma totalmente confiable y recomendable para contratar a profesionales freelance.
- DataFrame: una tabla de datos con filas y columnas etiquetadas
- Crear un DataFrame vacío
- Cómo crear un DataFrame a partir de una lista de listas
- Cómo crear un DataFrame a partir de un diccionario de listas
- Cómo crear un DataFrame a partir de una lista de diccionarios
- Cómo crear un DataFrame a partir de un array de NumPy
- Cómo crear un DataFrame a partir de un fichero CSV
- Cómo crear un DataFrame a partir de datos en el portapapeles
- Cómo crear una DataFrame a partir de una página web o un fichero HTML
- Cómo crear un DataFrame a partir de un fichero de Excel
- Cómo crear un DataFrame a partir de un fichero JSON
- Cómo crear un DataFrame a partir de una base de datos SQL
- Cómo crear un DataFrame a partir de objetos pickle, parquet o Feather, ficheros ORC, HDF, SPSS, SAS, Stata o consultas de Google BigQuery
- Tabla de resumen
DataFrame: una tabla de datos con filas y columnas etiquetadas
Antes de pasar a ver cómo cargar las distintas fuentes de datos en un DataFrame hay que dejar claro qué formato de datos representa.
Un DataFrame representa, ni más ni menos, a la típica tabla de datos de dos dimensiones, con filas y columnas. Además, cada fila y cada columna puede tener, opcionalmente, su nombre o etiqueta.
Así, y por ejemplo, podemos guardar en un DataFrame nuestro horario de clases, donde las columnas son los días, las filas son las horas, y los valores cada clase o asignatura. O también podríamos guardar la lista de salidas de vuelos donde las columnas representan el número de vuelo, la hora de salida y el destino.
Ten en cuenta que una tabla puede tener una única columna o una única fila, así que si te encuentras datos en este formato también son válidos para cargar en un DataFrame. ¡Incluso podría tener una fila y una columna, es decir, un solo valor!
Para terminar de aclararlo, te pongo un ejemplo de tabla para poder contrastar visualmente lo que te estoy contando:
| Nombre | Edad |
|---|---|
| Pepe | 37 |
| Juan | 42 |
| Laura | 40 |
DataFrameUsaremos una tabla similar a esta en algunos de los ejemplos de este artículo.

Uno de los mejores libros sobre Pandas y el análisis de datos en Python
De la mano del propio creador de Pandas, Wes McKinney.
Crear un DataFrame vacío
La primera situación en la que podemos encontrarnos, o la primera en la que pensamos, es que tenemos que ir creando de manera progresiva el DataFrame porque aún no tenemos los datos.
Por ejemplo, tal vez estemos ejecutando un proceso que va generando datos poco a poco y queremos ir guardando esos datos en un DataFrame.
Te envío todos los días un consejo para que cada día seas mejor en Python.
Siempre sobre Python y programación.
Más de 2500 personas como tú los reciben cada día.
Día que estás fuera, consejo sobre Python que te pierdes.
Antes de suscribirte consulta aquí la
Finalidad de recogida y tratamiento de datos personales: enviarte boletín informativo de Python y comunicaciones comerciales.
Legitimación: tu consentimiento.
Destinatarios: no se ceden a terceros. Los datos se almacenan en los servidores de marketing (GetResponse).
Derechos: podrás ejercer tus derechos de acceso, rectificación, limitación y supresión de datos en info @ codigopiton.com así como presentar una reclamación ante una autoridad de control.
Más información: política de privacidad, encontrarás información adicional sobre la recopilación y el uso de tu información personal.
La mejor opción para esto es crear un DataFrame vacío. Una vez creado ya podemos ir aportándole datos para que vaya creciendo poco a poco.
Lo primero que hay que entender es que nuestro DataFrame será una instancia o un objeto de la clase DataFrame de la librería pandas. Por eso, vamos a acudir a la manera más directa que existe para crear un objeto que es utilizando su constructor.
Asegúrate de tener instalada la librería. Puedes hacer uso del comando pip install pandas.
En este caso podemos invocar al constructor sin ningún parámetro y ya tendremos nuestro DataFrame listo para aceptar datos:
import pandas as pd
df = pd.DataFrame()Fíjate en que es necesario hacer el import de la librería para poder trabajar con ella. Además la renombramos como pd para que nos quede un código más corto.
Antes de poder introducir datos podemos definir algunas columnas, pues no puede haber tabla sin columnas. Lo vemos.
Cómo añadir columnas a un DataFrame
Ten en cuenta que la dimensión principal del DataFrame son las columnas, con lo que el acceso a las columnas siempre es un poco más directo que al de las filas. De hecho, usando la típica notación de corchetes accedemos antes a las columnas que a las filas, al contrario de lo que es habitual.
Una manera de añadir una nueva columna a un DataFrame es asignarle directamente los valores que debe tener esa columna, tal como haríamos en un diccionario y la notación de corchetes. Como en este caso no queremos introducir valores indico simplemente None.
df['Nombre'] = None
print(df)El resultado del código anterior es el siguiente, donde se puede como el DataFrame, aunque vacío, tiene una nueva columna llamada Nombre. Además puedes observar otra pieza de información que es Index, pero por ahora podemos ignorarla:
Empty DataFrame Columns: [Nombre] Index: []
Otra manera de agregar columnas es utilizando la función assign de DataFrame. Esta función nos permite añadir columnas a las ya creadas. Eso sí, no las añade al DataFrame original, sino que nos devuelve uno nuevo con las nuevas columnas más las columnas originales:
df['Nombre'] = None
df = df.assign(Edad=None)
print(df)El resultado de ejecutar el código anterior es:
Empty DataFrame Columns: [Nombre, Edad] Index: []
¡Cuidado! Si asignas columnas que ya existen sobreescribirás sus valores. En este caso no importa demasiado, porque aún no tenemos datos, pero piensa que ya podría haberlos.
Listo, ya sabemos cómo añadir columnas, pero... estarás de acuerdo conmigo que un DataFrame sin datos tampoco sirve de demasiado. Veamos cómo añadir datos entonces.
Cómo insertar datos en un DataFrame
Una vez que tenemos un DataFrame ya creado con sus columnas solo nos queda poder añadirle algunos datos. Existen múltiples formas de hacerlo. Vamos a ver un par de ellas.
Supongamos que tenemos los datos a insertar en listas, es decir, una lista para cada columna con los valores de cada fila para esa columna. Podemos hacer una asignación sencilla de la siguiente manera:
nombres = ['Juan', 'Laura', 'Pepe']
edades = [42, 40, 37]
df['Nombre'] = nombres
df['Edad'] = edades
print(df)El resultado de esta operación será el siguiente:
Nombre Edad 0 Juan 42 1 Laura 40 2 Pepe 37
¡Cuidado! Si asignas valores al DataFrame de esa manera todas las listas deben tener la misma longitud.
Fíjate que, de asignar así valores, no necesitamos previamente crear las columnas, pues la propia asignación ya crea la columna si no existe. Ten en cuenta que, de la misma manera, puedes estar machacando valores antiguos con los nuevos si la columna ya existe.
Una vez que tenemos algunos valores podemos añadir nuevos valores insertando filas completas. Esto nos sirve, como te decía antes, para poder insertar valores poco a poco según los vamos recibiendo o generando. Para eso puedes hacer uso de la función append de los objetos DataFrame, que añade la fila al final de la tabla.
A dicha función puedes proporcionarle un objeto Series de pandas, que representa una lista de valores o un objeto de tipo diccionario, donde a cada valor le corresponde como clave el nombre de la columna en la tabla. Veamos ambas formas en un mismo ejemplo:
15 conceptos fundamentales que necesitas conocer para aprender y dominar Python
Te voy a hacer cuatro regalos (no uno, no dos, no tres, cuatro) que hablan de estos 15 conceptos fundamentales de Python: mi Tutorial Básico Interactivo de Python, una cheat sheet de Python en español: La Hoja de Referencia de Python, una guía de ChatGPT y Python y 30 ejercicios de Python (es un reto para ti).
Estos regalos son exclusivos para los suscriptores de Código Pitón.
nombres = ['Juan', 'Laura', 'Pepe']
edades = [42, 40, 37]
df['Nombre'] = nombres
df['Edad'] = edades
nueva_fila = { 'Nombre': 'Paco', 'Edad': 29} # creamos un diccionario
df = df.append(nueva_fila, ignore_index=True)
nueva_fila = pd.Series(['Ana', 33], index=df.columns) # creamos un objeto Seris
df = df.append(nueva_fila, ignore_index=True)
print(df)Fíjate en varias cosas:
- La función
appenddevuelve un objeto nuevo con los nuevos valores por eso tenemos que hacer la asignacióndf = df.append(...). - Tenemos que indicar el parámetro
ignore_indexfijado aFalseen la función append para que no tenga en cuenta los índices de los nuevos datos que podrían venir indicados (aunque en este caso no lo hacen). Recuerda que podríamos añadir datos de otroDataFrameque sí tenga índices. - Al crear el objeto
Series, además de los datos nuevos hay que indicar las columnas (en el mismo orden que los datos). Para eso hago uso del parámetroindexy del atributocolumnsdelDataFrame, así me evito escribirlos a mano.
El resultado del código anterior es:
0 Juan 42
1 Laura 40
2 Pepe 37
3 Paco 29
4 Ana 33Puedes añadir varias filas a la vez proporcionando a la función append una lista de diccionarios o de Series, uno por fila. Eso sería más eficiente que realizar varias llamadas a la función, una llamada por cada fila.
Debes saber que, al igual que las columnas de un DataFrame pueden tener nombre, lo mismo pasa con las filas, como ya te adelanté antes. Cada fila puede tener su propio nombre o etiqueta. Puedes imaginarte para esto un calendario semanal donde cada fila representa un día de la semana. De esta forma podemos etiquetar cada fila con los nombres Lunes, Martes, Miércoles, etc.
Esto hace muy cómodo poder acceder a filas concretas sin necesidad de conocer su posición en la tabla. Vamos a crear un DataFrame, precisamente, para almacenar, por ejemplo, la medicación que una persona tiene que tomar por la mañana, tarde y noche para cada día de la semana.
Así, otra manera de añadir datos pasa por usar el atributo loc de un DataFrame. loc permite acceder a una fila concreta (o varias) a través de su nombre. Veamos el ejemplo:
import pandas as pd
df = pd.DataFrame()
# creamos las columnas
df['Mañana'] = None
df['Tarde'] = None
df['Noche'] = None
# añadimos filas por su nombre de fila
df.loc['Lunes'] = ['Tensión', 'Alergia', 'Sedante']
df.loc['Martes'] = ['Tensión', None, 'Alergia']
df.loc['Miércoles'] = ['Protector', 'Alergia', 'Tensión']
print(df)Esta forma tiene la ventaja de que no necesitamos indicar los nombres de columna para cada valor. Eso sí, es necesario proporcionar los valores en el orden apropiado. El resultado es el siguiente:
Mañana Tarde Noche
Lunes Tensión Alergia Sedante
Martes Tensión None Alergia
Miércoles Protector Alergia TensiónFíjate en que los martes por la tarde no hay medicación. Puedo indicar el valor None en ese caso.
Son precisamente estos nombres de etiquetas o de filas el conjunto de índices que print(df) pretendía mostrar por pantalla cuando el DataFrame estaba vacío.
¡Ojo! Ten en cuenta que loc reescribe una fila ya existente en caso de que el índice indicado ya exista en la tabla.
Por supuesto, existen muchas más formas de insertar datos, pero no es el objetivo de este artículo ver todas esas formas, si no que lo que queremos ver es las distintas maneras de crear un DataFrame. Ahora que ya hemos visto cómo crear uno vacío y cómo crear otro a partir de los valores de las columnas, pasemos a ver otras maneras.
Cómo crear un DataFrame a partir de una lista de listas
Si crear un DataFrame vacío puede ser la primera idea que tengamos cuando empezamos a aprender pandas, la segunda idea es crear uno a partir de una tabla de datos ya creada como una lista de listas, que también puede ser vista como una matriz. Para más información acerca del manejo de listas de listas échale un ojo a este artículo sobre cómo obtener una columna de una matriz en Python.
Para crear un DataFrame a partir de una lista de listas, llamada datos, por ejemplo, basta con invocar al constructor proporcionándole como parámetro la lista datos de la siguiente forma: DataFrame(datos). Dicha llamada devolverá el objeto DataFrame creado con los datos indicados y listo para usar.
Supón, entonces, que tienes una lista de tres listas con cuatro valores cada una que representa, por ejemplo, la siguiente tabla de datos:
10 11 12 13
20 21 22 23
30 31 32 33Ahora queremos crear el DataFrame a partir de dicha lista de listas. Podemos hacer lo siguiente:
import pandas as pd
datos = [[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33]]
df = pd.DataFrame(datos)
print(df)Este código genera el siguiente resultado por pantalla, donde podrás ver que, por defecto, los nombres de las columnas son 0, 1, 2 y 3 y los de las filas son 0, 1, y 2.
0 1 2 3
0 10 11 12 13
1 20 21 22 23
2 30 31 32 33Fíjate en que cada fila del DataFrame corresponde con cada fila de la lista de listas original.
Si lo que quieres es que cada fila de tu lista de listas pase a ser una columna en el DataFrame tendrás que transponer el DataFrame, es decir, intercambiar filas por columnas, a la hora de crearlo usando la función transpose de esta manera df = pd.DataFrame(datos).transpose().
Si necesitas nombres de columnas personalizados puedes añadir el parámetro columns a la llamada al constructor indicándole en una lista los nombres de las mismas.
De igual manera, si quieres darle nombres a las filas, puedes hacer lo mismo pero con el parámetro index:
Día que estás fuera, consejo sobre Python que te pierdes.
Antes de suscribirte consulta aquí la
Finalidad de recogida y tratamiento de datos personales: enviarte boletín informativo de Python y comunicaciones comerciales.
Legitimación: tu consentimiento.
Destinatarios: no se ceden a terceros. Los datos se almacenan en los servidores de marketing (GetResponse).
Derechos: podrás ejercer tus derechos de acceso, rectificación, limitación y supresión de datos en info @ codigopiton.com así como presentar una reclamación ante una autoridad de control.
Más información: política de privacidad, encontrarás información adicional sobre la recopilación y el uso de tu información personal.
import pandas as pd
datos = [[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33]]
columnas = ['C1', 'C2', 'C3', 'C4'] # definimos los nombres de las columnas
filas = ['F1', 'F2', 'F3'] # definimos los nombres de las filas
df = pd.DataFrame(datos, columns=columnas, index=filas)
print(df)Así, el resultado será el siguiente:
C1 C2 C3 C4
F1 10 11 12 13
F2 20 21 22 23
F3 30 31 32 33Cómo crear un DataFrame a partir de un diccionario de listas
Otro caso común es tener los datos de cada columna de la tabla deseada en un diccionario etiquetado por su nombre de columna.
Para crear un DataFrame a partir de un diccionario de listas basta con proporcionar dicho diccionario al constructor de la clase DataFrame de la siguiente manera: DataFrame(diccionario). Esta llamada devuelve un objeto DataFrame con los datos del diccionario con sus claves como nombres de columnas.
Supón que tienes un diccionario en el que hay almacenadas tres listas indexadas por las claves Nombre, Edad y Departamento. Simplemente debes proporcionarle dicho diccionario al constructor del DataFrame así:
import pandas as pd
datos = {
'Nombre' : ['Juan', 'Laura', 'Pepe'],
'Edad': [42, 40, 37],
'Departamento': ['Comunicación', 'Administración', 'Ventas']
}
df = pd.DataFrame(datos)
print(df)¡Y listo! Así de fácil obtenemos el siguiente resultado:
Nombre Edad Departamento
0 Juan 42 Comunicación
1 Laura 40 Administración
2 Pepe 37 VentasAsegúrate de que todas las listas del diccionario tengan la misma longitud.
Cómo crear un DataFrame a partir de una lista de diccionarios
Al contrario que el caso anterior, en el que teníamos los datos guardados por columnas en un diccionario de listas, puede suceder que los tengamos almacenados por filas en una lista de diccionarios. Parece un trabalenguas, ¿verdad?
Para crear un DataFrame a partir de una lista de diccionarios basta con proporcionar dicha lista al constructor de la clase DataFrame de la siguiente manera: DataFrame(lista). Esta llamada devuelve un objeto DataFrame con los datos de la lista con las claves como nombres de columnas.
El ejemplo queda de la siguiente manera en este caso:
import pandas as pd
datos = [
{'Nombre': 'Juan', 'Edad': 42, 'Departamento': 'Comunicación'},
{'Nombre': 'Laura', 'Edad': 44, 'Departamento': 'Administración'},
{'Nombre': 'Pepe', 'Edad': 37, 'Departamento': 'Ventas'}
]
df = pd.DataFrame(datos)
print(df)El resultado del código anterior es:
Nombre Edad Departamento
0 Juan 42 Comunicación
1 Laura 40 Administración
2 Pepe 37 VentasEl principal problema de esta solución es que debes asegurarte de que las claves de cada diccionario son correctas y consistentes entre sí. El DataFrame de destino creará tantas columnas como claves diferentes exista en los diccionarios. Si, por ejemplo, la clave asociada al nombre en un diccionario es Nombre, en otro es nombre y en otro es Name, acabaremos con tres columnas diferentes (se distingue entre mayúsculas y minúsculas) para el dato del nombre, cosa que no queremos. Además tendremos muchos valores None ya que si para una clave concreta no hay valores en los otros diccionarios es precisamente None lo que tendremos por defecto.
Cómo crear un DataFrame a partir de un array de NumPy
A menudo sucede que los datos que necesitamos manejar como un DataFrame los tenemos almacenados en un array de NumPy.
Para crear una DataFrame a partir de un array de NumPy hay que invocar al constructor de DataFrame proporcionándole dicho array de la siguiente manera: DataFrame(array). Si queremos indicar nombres de columnas deben proporcionarse en el parámetro columns.
En este caso también resulta muy sencillo como puedes observar. Previamente a la creación del DataFrame crearemos el array de NumPy (asegúrate de tener instalada la librería numpy):
import pandas as pd
import numpy as np
array = np.array([
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33]
])
columnas = ['C1', 'C2', 'C3', 'C4'] # esta lista también podría ser un array de NumPy
df = pd.DataFrame(array, columns = columnas)
print(df)Y el resultado, donde cada fila del array corresponde con una fila del DataFrame, es:
C1 C2 C3 C4
0 10 11 12 13
1 20 21 22 23
2 30 31 32 33Cómo crear un DataFrame a partir de un fichero CSV
A menudo tenemos los datos almacenados en un fichero CSV (siglas en ingles de Comma Separated Values, o valores separados por comas), que no es más que un fichero de texto en forma de tabla donde los valores están separados por comas (u otro símbolo). Además, estos ficheros suelen tener una primera línea que hace de cabecera con los nombres de las columnas.
Para crear un DataFrame a partir de los valores de un fichero CSV se pueden usar las funciones de pandas read_csv o read_table proporcionándoles el fichero y el carácter delimitador a usar. Estas funciones crean un nuevo DataFrame con los datos contenidos en el fichero.
Supón ahora que tenemos un fichero de texto, que se llama datos.csv, que tiene el siguiente contenido:
Nombre, Edad, Departamento
Juan, 42, Comunicación
Laura, 40, Administración
Pepe, 37, VentasEstos son los datos a partir de los cuales crearemos el DataFrame.
Una opción es usar la función read_csv, que es una función especialmente diseñada para leer ficheros CSV. Tiene multitud de parámetros, pero para ficheros sencillos solo necesitamos indicar el nombre del fichero y el carácter que se utiliza dentro de ese fichero como delimitador. En este caso, dicho carácter es la coma.
Veamos el ejemplo:
import pandas as pd
df = pd.read_csv('datos.csv', delimiter=',') # también se puede usar la función read_table
print(df)El resultado por pantalla será el siguiente:
Nombre Edad Departamento
0 Juan 42 Comunicación
1 Laura 40 Administración
2 Pepe 37 VentasEn este caso sencillo, puedes usar la función read_table exactamente de la misma manera y el resultado será el mismo.
Si el fichero a leer viene sin los nombres de las columnas debemos indicárselos a través del parámetro names de la siguiente manera: pd.read_csv('datos.csv', delimiter=',', names=['Nombre','Edad','Departamento']). Si no quremos nombres de columnas podemos proporcionarle el parámetro header=None.
Otra función similar a las que te acabo de presentar es read_fwf que lo que hace es generar la tabla de datos a partir de un fichero de texto donde los campos tienen una anchura fija por lo que no es necesario utilizar un carácter delimitador, pero el funcionamiento es muy similar y el ejemplo, que ya no hago aquí, es muy parecido.
Cómo crear un DataFrame a partir de datos en el portapapeles
Si tienes los datos en un formato de tabla similar a los del caso anterior separados por comas (o por otro delimitador) en el portapapeles del sistema, pandas te permite leerlos de ahí directamente sin necesidad de crear un fichero para hacerlo. Esto es interesante porque nos permite crear un DataFrame a partir de datos obtenidos de diversas fuentes de manera dinámica y muy rápida con solo copiar los datos al portapapeles.
Para crear un DataFrame a partir de valores separados por comas copiados en el portapapeles del sistema se puede usar la función de pandas read_clipboard proporcionándole el carácter delimitador a usar. Esta función crea un nuevo DataFrame con los datos contenidos en el portapapeles.
Haz la prueba seleccionando los datos del siguiente ejemplo y copiándolos:
Nombre, Edad, Departamento
Juan, 42, Comunicación
Laura, 40, Administración
Pepe, 37, VentasAhora sólo tienes que utilizar la función read_clipboard de la siguiente manera y ya tendrás tu DataFrame. ¡Casi mágico!
import pandas as pd
df = pd.read_clipboard(',')
print(df)El resultado será el mismo que en el caso anterior.
Si el carácter separador de campos no son uno o más espacios, debes indicar el carácter o cadena de texto que quieras pasándole un parámetro a la función, por ejemplo, read_clipboard(','). Si invocas a la función por sin parámetros se utilizarán los espacios como separadores.
Cómo crear una DataFrame a partir de una página web o un fichero HTML
Si lo que queremos es obtener los datos de una tabla HTML de un fichero o una página web pandas nos facilita las cosas. Sí, también en este caso que puede parecer más complicado.
Para crear un DataFrame a partir de las tablas de una página web o de un fichero HTML se puede usar la función de pandas read_html proporcionándole el fichero o URL a leer. Esta función busca las etiquetas <table> y crea una lista de DataFrame con cada una de las tablas del documento.
La función read_html busca las etiquetas <table> y los elementos <tr> (fila), <th> (cabecera) y <td> (dato) y genera un DataFrame por cada una de las tablas encontradas, de forma que siempre devuelve una lista con los DataFrame generados.
Hay que tener en cuenta todos los problemas de analizar y leer páginas web, así que es probable que tengas que hacer alguna limpieza en tus DataFrame después de la lectura.
Necesitaremos la librería lxml que sirve para procesar y analizar ficheros XML y HTML en Python. Asegúrate de instalarla con el comando pip install lxml.
A continuación te muestro un pequeño fichero HTML que he generado con dos tablas diferentes y que he llamado datos.html.
<html>
<head>
<meta charset="UTF-8">
<title>Página de prueba con tablas HTML - Código Pitón</title>
</head>
<body>
<h1>Cómo crear DataFrames a partir de ficheros HTML<h1>
<h2>Tabla 1</h2>
<table>
<tr>
<th>Nombre</th>
<th>Edad</th>
</tr>
<tr>
<td>Juan</td>
<td>42</td>
</tr>
<tr>
<td>Laura</td>
<td>40</td>
</tr>
<tr>
<td>Pepe</td>
<td>37</td>
</tr>
</table>
<h2>Table 2</h2>
<table>
<tr>
<th>A</th>
<th>B</th>
<th>C</th>
</tr>
<tr>
<td>4</td>
<td>4</td>
<td>3</td>
</tr>
<tr>
<td>5</td>
<td>9</td>
<td>0</td>
</tr>
<tr>
<td>6</td>
<td>5</td>
<td>2</td>
</tr>
<tr>
<td>0</td>
<td>6</td>
<td>3</td>
</tr>
<tr>
<td>9</td>
<td>1</td>
<td>8</td>
</tr>
</table>
</body>
</html>Con este fichero, que puedes copiar y pegar en un fichero vacío, ejecutaremos el siguiente ejemplo. Puedes abrir el fichero HTML usando un navegador web para ver su contenido y las tablas creadas. El ejemplo genera una lista de DataFrame con dos objetos, uno por cada tabla del documento HTML .Dicha lista se muestra a continuación por pantalla:
import pandas as pd
dfs = pd.read_html('datos.html')
for df in dfs:
print(df, '\n')El resultado que obtenemos es el siguiente:
Nombre Edad
0 Juan 42
1 Laura 40
2 Pepe 37
A B C
0 4 4 3
1 5 9 0
2 6 5 2
3 0 6 3
4 9 1 8 Es posible que, debido a varios factores, la lectura con la librería lxml pueda fallar, en ese caso se utilizarían la librerías html5lib o bs4 que sería conveniente que también tuvieras instaladas. Si prefieres que la lectura se haga directamente con esas liberías puedes indicarle a la función el parámetro flavor='bs4'.
Cómo crear un DataFrame a partir de un fichero de Excel
Otro caso habitual es el de tener los datos en un fichero de Microsoft Excel, o en general, de una hoja de cálculo compatible, como pueden ser las de formato abierto del paquete LibreOffice.
Para crear un DataFrame a partir de una hoja de cálculo o un fichero de Excel se puede usar la función de pandas read_excel proporcionándole el nombre del fichero. Esta función abre y lee el fichero y crea un DataFrame con su contenido listo para su uso.
La imagen a continuación muestra los datos contenidos en una hoja de cálculo, en este caso generada con Google Drive y guardada en formato xlsx con el nombre datos.xlsx.
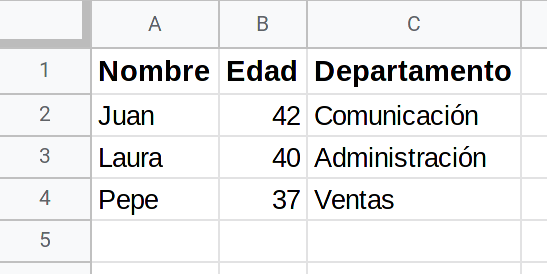
Para cargar los datos del fichero y generar el DataFrame usaremos la función read_excel. Esta función utiliza internamente otra librería encargada de leer los datos del fichero de origen. Como en este caso el formato del fichero es de Excel la librería a utilizar es openpyxl que debemos instalar mediante el comando pip install openpyxl. Si necesitamos leer un fichero en formato Open Document Format (como los de LibreOffice, por ejemplo), la librería que debemos instalar sera odf.
Una vez instalada la librería necesaria ya podemos utilizar la función read_excel de la siguiente sencilla manera:
import pandas as pd
df = pd.read_excel('datos.xlsx')
print(df)¿Fácil, no? El resultado por pantalla será el siguiente:
Nombre Edad Departamento
0 Juan 42 Comunicación
1 Laura 40 Administración
2 Pepe 37 VentasPuede suceder que la tabla que queramos leer esté ubicada en una fila y columna determinada del fichero. En ese caso tendremos que indicarle las filas que debe ignorar con el parámetro skiprows y las columnas que debe leer con el parámetro usecols.
Además, es posible que la tabla que necesitamos cargar no esté en la primera hoja del documento. Podemos usar el parámetro sheet_name para indicar la hoja en la que debe buscar los datos. Podemos indicarle el número de hoja, teniendo en cuenta que la primera es la 0, o bien el nombre de la hoja.
Por ejemplo, si la tabla de datos comenzara en la fila 3 y la columna B de una hoja llamada Empleados dentro del fichero datos.xlsx podríamos cargar los datos de la siguiente manera: df = pd.read_excel('datos.xlsx', sheet_name='Empleados', usecols='B:D', skiprows=2).
Cómo crear un DataFrame a partir de un fichero JSON
Otra posibilidad es que los datos los tengamos en un fichero JSON, que es muy popular en la actualidad.
Para crear un DataFrame a partir de un fichero JSON se puede usar la función de pandas read_json indicándole un nombre de fichero de la siguiente manera pandas.read_jason('datos.json'). Esta función crea un nuevo DataFrame con los datos contenidos en el fichero proporcionado.
Vamos a generar un DataFrame con los mismos datos de los ejemplos anteriores, solo que, en este caso, el fichero de origen está en formato JSON:
[
{
"Nombre": "Juan",
"Edad": 42,
"Departamento": "Comunicación"
},
{
"Nombre": "Laura",
"Edad": 40,
"Departamento": "Administración"
},
{
"Nombre": "Pepe",
"Edad": 37,
"Departamento": "Ventas"
}
]Ahora solo tienes que utilizar la función read_json que se encargará de leer los datos del fichero indicado y crear el DataFrame:
import pandas as pd
df = pd.read_json('datos.json')
print(df)Y por no seguir repitiéndome, el resultado será el mismo que en los casos anteriores.
Cómo crear un DataFrame a partir de una base de datos SQL
Veamos un ejemplo un poco más complejo aprovechando la potencia de las bases de datos SQL.
Parar crear un DataFrame a partir de una base de datos SQL se puede usar la función de pandas read_sql, a la que se le debe proporcionar un nombre de tabla o una consulta SQL y una conexión con la base de datos. La función devolverá el DataFrame con los datos correspondientes listo para usar.
Vamos a suponer que, esta vez, tenemos dos tablas de datos diferentes en una base de datos. Una de empleados y otra de departamentos. La tabla de empleados tiene columnas como el código del empleado, el nombre, la edad y el código del departamento donde trabaja. La tabla de departamentos tiene como columnas el código del departamento, el nombre y la ubicación.
Lo que queremos hacer es crear un DataFrame en el que tengamos las columnas de ambas tablas, que tendremos que unir mediante una operación de join en la columna de código de departamento.
En tu caso ya tendrás tu base de datos creada en un sistema de gestión de bases de datos determinado, como pueden ser MariaDB o PostgreSQL. En este ejemplo voy a trabajar con SQLite.
Asegúrate de tener instalada la librería SQLAlchemy, pues pandas la necesita para conectarse con la base de datos. Puedes instalarla con el comando pip install sqlalchemy.
He creado una base de datos llamada base_de_datos.db (original, ¿no?) con la estructura que te cuento más arriba. Además he insertado algunos datos en las dos tablas. Te dejo aquí el código SQL que te permite crear la base de datos exactamente igual que la mía para que puedas probar este ejemplo si te interesa:
BEGIN TRANSACTION;
CREATE TABLE IF NOT EXISTS "empleados" (
"codigo" INTEGER NOT NULL,
"nombre" TEXT,
"edad" INTEGER,
"departamento" INTEGER,
PRIMARY KEY("codigo" AUTOINCREMENT)
);
CREATE TABLE IF NOT EXISTS "departamentos" (
"codigo" INTEGER NOT NULL,
"nombre" TEXT,
"ubicacion" TEXT,
PRIMARY KEY("codigo" AUTOINCREMENT)
);
INSERT INTO "empleados" VALUES (1,'Juan',42,1);
INSERT INTO "empleados" VALUES (2,'Laura',40,2);
INSERT INTO "empleados" VALUES (3,'Pepe',37,3);
INSERT INTO "empleados" VALUES (4,'Ana',29,2);
INSERT INTO "empleados" VALUES (5,'María',32,3);
INSERT INTO "departamentos" VALUES (1,'Comunicación','Primera planta');
INSERT INTO "departamentos" VALUES (2,'Administración','Planta baja');
INSERT INTO "departamentos" VALUES (3,'Ventas','Primera planta');
COMMIT;Con la base de datos creada solo nos resta crear algunos DataFrames. Vamos a empezar por la opción más directa, que es cargar un DataFrame con cada una de las tablas.
Para esto basta con utiliza la función read_sql a la que debemos darle dos parámetros. El primero es el nombre de la tabla que queremos leer. El segundo es una cadena de texto de conexión a la base de datos, que en nuestro caso será del estilo sqlite:///nombre_base_de_datos.db. Lo vemos:
import pandas as pd
df_empleados = pd.read_sql('empleados', 'sqlite:///base_de_datos.db')
df_departamentos = pd.read_sql('departamentos', 'sqlite:///base_de_datos.db')
print('Empleados:', df_empleados, sep='\n')
print('Departamentos:', df_departamentos, sep='\n')Si te fijas ahora tenemos dos DataFrame, que son df_empleados y df_departamentos. Al mostrarlos por pantalla obtenemos lo siguiente:
Empleados:
codigo nombre edad departamento
0 1 Juan 42 1
1 2 Laura 40 2
2 3 Pepe 37 3
3 4 Ana 29 2
4 5 María 32 3
Departamentos:
codigo nombre ubicacion
0 1 Comunicación Primera planta
1 2 Administración Planta baja
2 3 Ventas Primera plantaAsí de simple y así de rápido. Pero ahora vamos a hacer algo un poco más complejo, pues lo que quiero obtener es un único DataFrame con todos los campos de ambas tablas combinados de forma que a cada empleado le siga la información de su departamento y no solo su código.
Esto lo puedo resolver con una operación de join sencilla entre las dos tablas que podemos realizar de la siguiente manera, donde además selecciono solo algunos campos, pues no me interesan los codigos. La consulta SQL queda de la siguiente manera:
select e.nombre, e.edad, d.nombre as departamento, d.ubicacion
from empleados as e inner join departamentos as d
on e.departamento = d.codigo;La potencia de la función read_sql es que nos permite indicar una consulta SQL para obtener los datos que necesitamos para luego tener que manipular lo menos posible el DataFrame. Basta con indicar la consulta en lugar del nombre de la tabla y lo tenemos listo. Código:
import pandas as pd
consulta = '''
select e.nombre, e.edad, d.nombre as departamento, d.ubicacion
from empleados as e inner join departamentos as d
on e.departamento = d.codigo;
'''
df = pd.read_sql(consulta, 'sqlite:///base_de_datos.db')
print(df)Y el resultado es el siguiente:
nombre edad departamento ubicacion
0 Juan 42 Comunicación Primera planta
1 Laura 40 Administración Planta baja
2 Pepe 37 Ventas Primera planta
3 Ana 29 Administración Planta baja
4 María 32 Ventas Primera plantaCómo crear un DataFrame a partir de objetos pickle, parquet o Feather, ficheros ORC, HDF, SPSS, SAS, Stata o consultas de Google BigQuery
Existen otros objetos o ficheros de datos menos comunes o más especializados a partir de los cuales también se puede generar un DataFrame. Si has leído parte de este artículo ya habrás entendido la tónica general de creación de un DataFrame. Por tanto, no voy a poner ejemplos de todos estos formatos porque el artículo se extendería demasiado (y creo que ya es demasiado largo), pero sí quiero dejarte aquí un listado de las funciones utilizadas para leer estos objetos y ficheros para que seas consciente de que existen.
Todas estas funciones, así como todas las que ya te he contado pueden ser consultadas en la documentación oficial de pandas.
| Objeto o fichero | Función |
|---|---|
| Pickle (serialización) | read_pickle |
| PyTables, HDF5 | read_hdf |
| Feather | read_feather |
| Parquet | read_parquet |
| ORC | read_orc |
| SAS | read_sas |
| SPSS | read_spss |
| Google BigQuery | read_gbq |
| Stata | read_stata |
Tabla de resumen
Hemos visto varias formas para crear un DataFrame con pandas y Python. Si has leído el artículo completo, verás que todas las maneras son muy parecidas, aunque cada una tiene sus particularidades. La idea aquí es que pandas quiere hacernos la vida muy fácil, como puedes ver.
Te presento aquí, a modo de resumen, una tabla con todas las formas y funciones que hemos visto para crear un DataFrame para que la tengas de referencia rápida.
| Origen de los datos | Ejemplo |
|---|---|
| Sin datos | df = pd.DataFrame(columns=['Columna 1', 'Columna 2'])df['Columna 3'] = Nonedf['Columna 4'] = None |
| Lista de listas, lista de diccionarios | df = pd.DataFrame(lista) |
| Diccionario de listas | df = pd.DataFrame(diccionario) |
| Array de NumPy | df = pd.DataFrame(array) |
| Fichero CSV | df = pd.read_csv('datos.csv')df = pd.read_table('datos.csv', delimiter=',') |
| Fichero con campos de anchura fija | df = pd.read_fwf('datos.fwf') |
| Datos en portapapeles | df = pd.read_clipboard() |
| Web o ficheros HTML | dfs = pd.read_html('datos.html')dfs = pd.read_html(url) |
| Hoja de cálculo | df = pd.read_excel('datos.xlsx') |
| Fichero JSON | df = pd.read_json('datos.json') |
| Base de datos SQL | df = pd.read_sql(tabla, conexion_bd)df = pd.read_sql(consulta, conexion_bd) |
| Otros formatos | Ver tabla 2 |
¡Alto! ¿Necesitas que alguien te ayude con Pandas? ¿Quieres que alguien lo haga por ti?
Puedes contratar (a un precio muy, muy económico) a un programador de Python y Pandas en Fiverr.
Te recomiendo a estos dos (ambos hablan español), que están especializados en Pandas a los que podrás pedirles lo que necesites:
- Abdelmoulaelbou (Análisis de datos utilizando Python y Pandas)
- Carlosswanton (Análisis y visualización de datos con Python y Pandas)
Solo tienes que registrarte en Fiverr y contratarlos, ¡es muy sencillo! (links de afiliado de Fiverr). Yo mismo he usado Fiverr en diversas ocasiones y es una plataforma totalmente confiable y recomendable para contratar a profesionales freelance.
Si te ha gustado el artículo o te ha ayudado a arrancar con esto de pandas, por favor, no dudes en compartirlo con aquellos a quien pueda interesarles utilizando los botones que encontrarás más abajo. ¡Muchas gracias por leer y compartir!
Te envío todos los días un consejo para que cada día seas mejor en Python.
Siempre sobre Python y programación.
Más de 2500 personas como tú los reciben cada día.
Día que estás fuera, consejo sobre Python que te pierdes.
Antes de suscribirte consulta aquí la
Finalidad de recogida y tratamiento de datos personales: enviarte boletín informativo de Python y comunicaciones comerciales.
Legitimación: tu consentimiento.
Destinatarios: no se ceden a terceros. Los datos se almacenan en los servidores de marketing (GetResponse).
Derechos: podrás ejercer tus derechos de acceso, rectificación, limitación y supresión de datos en info @ codigopiton.com así como presentar una reclamación ante una autoridad de control.
Más información: política de privacidad, encontrarás información adicional sobre la recopilación y el uso de tu información personal.