Cuando hablamos de análisis y visualización de datos un artefacto muy interesante es el histograma. Como ya sabes, un histograma es una representación gráfica que nos permite ver la distribución de las frecuencias de una muestra. Te cuento en este artículo algunas maneras de realizar histogramas en Python.
Para hacer un histograma en Python es necesario contar las veces que aparece cada valor en cada intervalo en el conjunto de valores. Después se puede hacer una representación textual del cálculo realizado. También se puede usar una librería como Matplotlib, Seaborn, Bokeh, Altair o Plotly.
En este artículo vas a aprender a dibujar un histograma de un conjunto de datos utilizando Python sin ninguna librería añadida. Además, te contaré cómo hacerlo utilizando seis librerías de visualización de datos diferentes, para que puedas elegir la que más se adapta a tu proyecto.
La idea que tengo es explicarte la manera más sencilla de hacer histogramas con cada uno de los métodos, ya que esto, como tantas otras cosas en la vida, se puede complicar mucho.
- Pasos en la construcción de un histograma
- Cómo hacer un histograma en Python puro
- Cómo calcular las frecuencias con NumPy
- Histograma con Matplotlib
- Histograma con Pandas y Matplotlib
- Histograma con Seaborn
- Histograma con Bokeh
- Histograma con Plotly
- Histograma con Altair
- Histograma con pygal
- Ejemplo con datos reales
- Conclusión: ¿qué método debo elegir?
Pasos en la construcción de un histograma
Antes de entrar de lleno en los diferentes métodos para hacer un histograma en Python que te propongo en este artículo, quiero aclararte que, con independencia del método a usar, es necesario realizar siempre tres pasos sencillos:
- Determinar los intervalos a representar. Debemos dividir los datos agrupándolos por intervalos consecutivos y que no se solapen entre sí. Así podremos representar la frecuencia de cada uno de estos intervalos. En un histograma cada una de las barras corresponde a un intervalo diferente. Por ejemplo, si nuestra muestra de datos contiene los valores 2, 4, 5, 5, 8, 9 y 9, podríamos dividir el conjunto en dos intervalos: de 1 a 5 y de 6 a 10.
- Calcular la frecuencia de cada intervalo. Una vez que los intervalos están determinados es necesario contar cuántos valores pertenecen a cada intervalo. Esa cuenta es lo que llamamos la frecuencia del intervalo. Para el ejemplo anterior, tendríamos que para el intervalo 1-5 tenemos 4 valores (2, 4, 5, 5) y que para el intervalo 6-10 tenemos 3 valores (8, 9, 9). Es decir, 4 y 3 son las frecuencias de los intervalos propuestos.
- Dibujar el histograma en sí. Una vez que tenemos los intervalos y las frecuencias calculadas solo resta hacer alguna representación gráfica. Para ello podemos hacer alguna representación textual o utilizar una librería de visualización de datos.
Estos tres pasos habrá que seguirlos siempre. A veces no tendremos que hacer el cálculo de las frecuencias (paso 2) porque la propia librería de visualización lo hará por nosotros. Otras veces no tendremos que determinar a mano los intervalos y podemos dejar que la librería elija los que le parecen mejor. En cualquier caso, es importante que tengas esta pequeña receta de tres pasos en la cabeza porque, de una manera u otra, siempre están ahí.
Cómo hacer un histograma en Python puro
Te presento aquí la primera de las alternativas. Aunque quizá sea la menos científica y la más simple de todas, nos puede venir bien cuando tenemos que hacer un único histograma sencillo con un conjunto de datos pequeño. De esta manera, no tenemos que utilizar (ni aprender) una librería compleja de visualización para esta tarea. Como se suele decir "no matemos moscas a cañonazos".
Vamos a suponer que nuestro conjunto de datos son las edades de un grupo de personas y que son la siguientes: 12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19. Como ves hay un poco de todo entre las edades 12 y 20 años.
Puede suceder que, cuando tratamos con datos enteros, que los intervalos que queremos definir son cada uno de los posibles valores en el conjunto. Es decir, y en este caso, sería tomar los siguientes intervalos: de 12 a 13 (sin incluir el último), de 13 a 14, de 14 a 15, etc.
Como los valores son números enteros, en el intervalo 12 - 13, o mejor representado matemáticamente [12, 13), donde el corchete indica que el 12 está incluido (intervalo cerrado por la izquierda) y el paréntesis indica que el 13 está excluido (intervalo abierto por la derecha), solo los valores que sean 12 pertenecerán a dicho intervalo (pues no pueden aparecer valores como 12,5 o 12,85).
En este caso, tendremos tantos intervalos como números diferentes haya en el conjunto de datos, que en este caso son 20 - 12 + 1 = 9 intervalos.
Con los intervalos bien definidos, el segundo paso consiste en calculas las frecuencias, es decir, contar el número de valores que pertenecen a cada intervalo. Pues bien, vamos a definir el conjunto de valores como una lista en Python y a calcular las frecuencias para los 9 intervalos definidos:
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
mapa_edades = {}
for edad in edades:
if edad in mapa_edades:
mapa_edades[edad] += 1
else:
mapa_edades[edad] = 1
for valor in sorted(mapa_edades):
print(f'{valor}: {mapa_edades[valor]}')La manera en la que puedes contar los valores de cada intervalo es por medio del uso de un diccionario. Así, a cada valor diferente del conjunto de edades le asignamos su frecuencia. Simplemente tenemos que recorrer la lista de edades y para cada una de ellas comprobar si existen en el diccionario. Si no existen inicializamos la cuenta para esa edad en 1 (ya hemos encontrado un valor de esa intervalo). Si ya existe, simplemente incrementamos la cuenta en una unidad.
Al terminar el bucle, ya tenemos en el diccionario las frecuencias calculadas. Si lo ordenamos y lo mostramos por pantalla podemos comprobar el resultado de las cuentas:
12: 3
13: 5
14: 1
15: 2
16: 1
17: 2
18: 1
19: 2
20: 2Esto, que es una representación textual de las frecuencias todavía no es un histograma. Para que sea un histograma tenemos que hacer una representación con barras (o algo que se le parezca) donde las barras son proporcionales a las frecuencias.
Para resolver esto basta con dibujar un símbolo tantas veces como indica la frecuencia. Por ejemplo, si la frecuencia es 3 podemos dibujar tres asteriscos de la siguiente manera ***. Vamos a ver cómo queda el resultado:
Te envío todos los días un consejo para que cada día seas mejor en Python.
Siempre sobre Python y programación.
Más de 2500 personas como tú los reciben cada día.
Día que estás fuera, consejo sobre Python que te pierdes.
Antes de suscribirte consulta aquí la
Finalidad de recogida y tratamiento de datos personales: enviarte boletín informativo de Python y comunicaciones comerciales.
Legitimación: tu consentimiento.
Destinatarios: no se ceden a terceros. Los datos se almacenan en los servidores de marketing (GetResponse).
Derechos: podrás ejercer tus derechos de acceso, rectificación, limitación y supresión de datos en info @ codigopiton.com así como presentar una reclamación ante una autoridad de control.
Más información: política de privacidad, encontrarás información adicional sobre la recopilación y el uso de tu información personal.
12: *** 13: ***** 14: * 15: ** 16: * 17: ** 18: * 19: ** 20: **
Y ahora sí que lo tenemos. Como te decía, esta representación es un poco burda y nos sirve solamente si el conjunto de datos es pequeño.
Otra manera un poco menos manual de calcular las frecuencias es utilizar la clase Counter del modulo collections. Dicha clase nos genera un diccionario igual que el que hemos hecho a mano, así, la solución completa nos quedaría como sigue:
from collections import Counter
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
mapa_edades = Counter(edades)
for valor in sorted(mapa_edades):
print(f'{valor}: {"*" * mapa_edades[valor]}')Vamos a ponernos ahora en la situación de que queremos definir (paso 1) unos intervalos más amplios (o estamos trabajando con valores reales y no enteros). Primero creamos una lista con los intervalos, donde cada intervalo es una tupla de dos valores que representan los bordes de un intervalo cerrado por la izquierda y abierto por la derecha. Es decir, para el intervalo (10, 13) consideramos todos los valores entre 10 y 13 incluyendo el 10 y excluyendo el 13, es decir, matemáticamente [10, 13).
Después creamos un diccionario donde las claves serán cada uno de los intervalos y lo inicializamos a cero con la ayuda de la función dict y la función zip. Si no tienes muy claro cómo trabaja esta última función puedes mirar este artículo donde te cuento cómo recorrer dos listas a la vez en Python y en el que te la explico.
A continuación contamos los valores de cada intervalo de manera similar al ejemplo anterior y finalmente dibujamos el histograma con asteriscos:
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
intervalos = [(10, 13), (13, 16), (16, 19), (19, 22)]
mapa_edades = dict(zip(intervalos, [0] * len(intervalos)))
for edad in edades:
for intervalo in mapa_edades:
if intervalo[0] <= edad < intervalo[1]:
mapa_edades[intervalo] += 1
break
for valor in sorted(mapa_edades):
print(f'{valor}: {"*" * mapa_edades[valor]}')Al ejecutar el código anterior obtendremos el siguiente resultado:
(10, 13): ***
(13, 16): ********
(16, 19): ****
(19, 22): ****Vamos a ponernos un poco más científicos a partir de ahora, y te voy a explicar cómo dibujar histogramas con diversas librerías de visualización. Pero antes vamos a ver una manera de calcular las frecuencias de manera sencilla.
Cómo calcular las frecuencias con NumPy
Un gran aliado en el análisis de datos y en el cálculo científico es la librería NumPy. NumPy nos permite, entre otras cosas, calcular las frecuencias de cada intervalo de manera sencilla sin la necesidad de llevar nosotros la cuenta.
Así, disponemos de una función histogram que sirve para calcular las frecuencias de cada intervalo en el conjunto de datos. ¡Ojo! Que NumPy no dibuja nada, y aunque la función se llame de esa manera, lo único que hace es calcular las frecuencias.
Para trabajar con esta función tenemos que proporcionarle dos parámetros: el conjunto de datos y los intervalos. Los intervalos se llaman bins, de forma que es ese nombre el que se maneja en este tipo de librerías. El conjunto de datos será nuestra lista con valores. En el caso de los intervalos tenemos dos opciones principales:
- Proporcionarle el número de intervalos. De esta manera, es la propia función la que determina los extremos de los intervalos, y lo hace teniendo en cuenta los valores mínimo y máximo del conjunto de datos. Todos los intervalos definidos así tienen la misma anchura. Además, hay que tener en cuenta que el último intervalo es cerrado también por la derecha. Si queremos evitar esto, podemos proporcionar un rango diferente (parámetro range) para simular que el valor máximo es otro que no está incluido en el conjunto de datos. Aunque esto solo tiene sentido en algunos casos, por ejemplo, cuando tratamos con números enteros.
- Proporcionarle en una lista o tupla los extremos o bordes de los intervalos. De esta manera podemos hacer intervalos personalizados y que no sean del mismo ancho si así lo deseamos. Debemos proporcionar los extremos de manera creciente. Hay que tener en cuenta, nuevamente, que el último intervalo será cerrado por la derecha.
La función histogram nos devolverá, al invocarla, dos arrays (es el tipo de dato que define la propia librería NumPy y que es compatible con muchas librerías de tratamiento y visualización de datos). El primer array contiene las frecuencias de los intervalos y el segundo contiene los extremos de los intervalos. Veamos algunos ejemplos para que te quede claro:
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
#calculamos las frecuencias para 8 intervalos (bins=8)
frecuencias, extremos = histogram(edades, bins=8)
print(frecuencias, extremos)
#calculamos las frecuencias para 9 intervalos (bins=9)
#indicamos que los valores van de 12 a 21 para incluir el intervalo 20-21
frecuencias, extremos = histogram(edades, bins=9, range=(12,21))
print(frecuencias, extremos)
#calculamos las frecuencias para intervalos personalizados
# [10, 13) [13, 15) [15, 20]
frecuencias, extremos = histogram(edades, bins=(10, 13, 15, 20))
print(frecuencias, extremos)Este código imprimirá lo siguiente por pantalla al ser ejecutado:
[3 5 1 2 1 2 1 4] [12. 13. 14. 15. 16. 17. 18. 19. 20.]
[3 5 1 2 1 2 1 2 2] [12. 13. 14. 15. 16. 17. 18. 19. 20. 21.]
[ 3 6 10] [10 13 15 20]¿Por qué te cuento todo esto? Porque será muy útil para utilizarlo con algunas librerías de visualización de datos, que ya esperan que el formato de los datos sea el de NumPy. Y, porque, cómo ves, solo esta función ya nos permite hacer los cálculos de las frecuencias y los intervalos de manera muy sencilla. Con esto, ¡solo nos queda dibujar!
Histograma con Matplotlib
Matplotlib es una de las principales y más conocidas librerías de visualización y generación de gráficos para Python. De hecho, hay otras librerías que se basan en ella, como podremos ver más adelante.
Para realizar un histograma con Matplotlib hay que utilizar el módulo pyplot, que permite la construcción de un gráfico, y la función hist, a la que hay que proporcionarle el conjunto de datos y los intervalos deseados. Finalmente basta con invocar a la función show para obtener el histograma.
Como puedes ver, en esencia es muy sencillo. Aunque nosotros, en el ejemplo, vamos a configurar un poco el gráfico para:
- Añadir un título con la función
title. - Añadir etiquetas en los ejes con las funciones
xlabeleylabel. - Cambiar el número de divisiones en el eje X con la función
xticks. - Cambiar el color de las barras con el parámetro
colorde la funciónhist. - Cambiar el ancho de las barras con el parámetro
rwidthde la funciónhist.
De esta manera, el código queda tan simple como lo siguiente:
import matplotlib.pyplot as plot
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
intervalos = range(min(edades), max(edades) + 2) #calculamos los extremos de los intervalos
plot.hist(x=edades, bins=intervalos, color='#F2AB6D', rwidth=0.85)
plot.title('Histograma de edades - matplotlib - codigopiton.com')
plot.xlabel('Edades')
plot.ylabel('Frecuencia')
plot.xticks(intervalos)
plot.show() #dibujamos el histogramaLa ejecución del código anterior genera un bonito gráfico con el histograma buscado como se puede ver en la siguiente figura:
15 conceptos fundamentales que necesitas conocer para aprender y dominar Python
Te voy a hacer cuatro regalos (no uno, no dos, no tres, cuatro) que hablan de estos 15 conceptos fundamentales de Python: mi Tutorial Básico Interactivo de Python, una cheat sheet de Python en español: La Hoja de Referencia de Python, una guía de ChatGPT y Python y 30 ejercicios de Python (es un reto para ti).
Estos regalos son exclusivos para los suscriptores de Código Pitón.
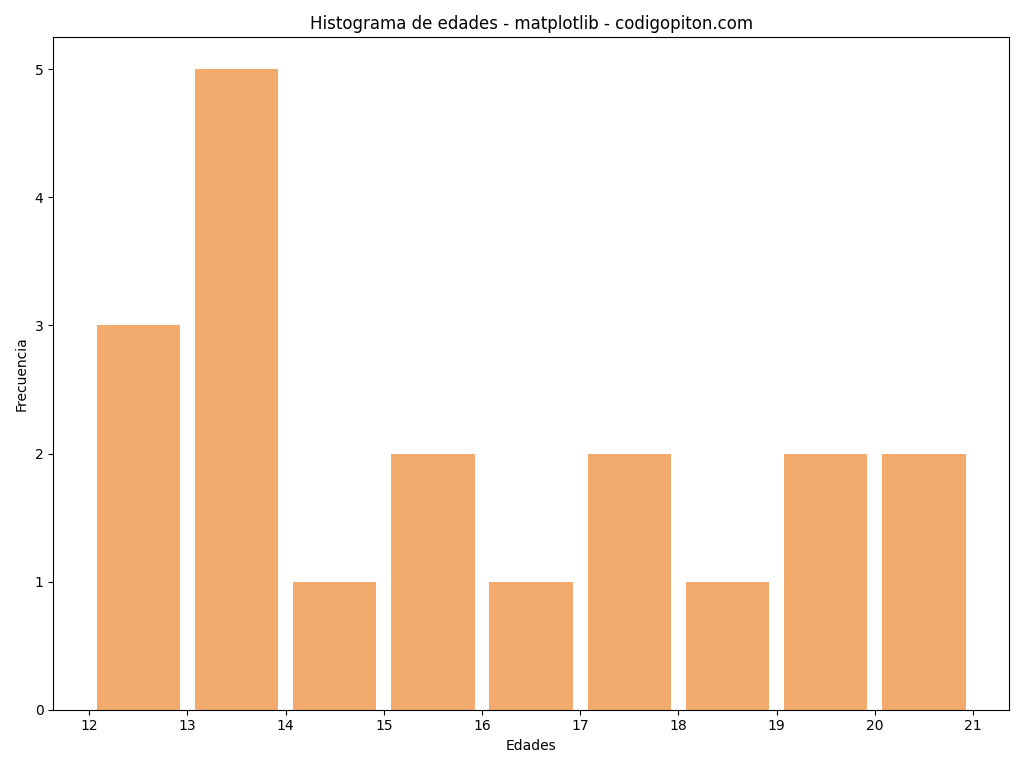
Ya ves que el código para generarlo es muy fácil y simple. La función hist utiliza internamente a la función histogram de NumPy explicada previamente de forma que no tenemos que hacer nosotros el cálculo de las frecuencias.
Veamos ahora el caso en el que queremos calcular las frecuencias para otros intervalos. Para esto solo tenemos que proporcionar mediante el parámetro bins una lista con los extremos de los intervalos deseados de la siguiente manera:
import matplotlib.pyplot as plot
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
intervalos = [10, 13, 16, 19, 22] #indicamos los extremos de los intervalos
plot.hist(x=edades, bins=intervalos, color='#F2AB6D', rwidth=0.85,)
plot.title('Histograma de edades - matplotlib - codigopiton.com')
plot.xlabel('Edades')
plot.ylabel('Frecuencia')
plot.xticks(intervalos)
plot.show() #dibujamos el histogramaEl histograma obtenido es el siguiente:
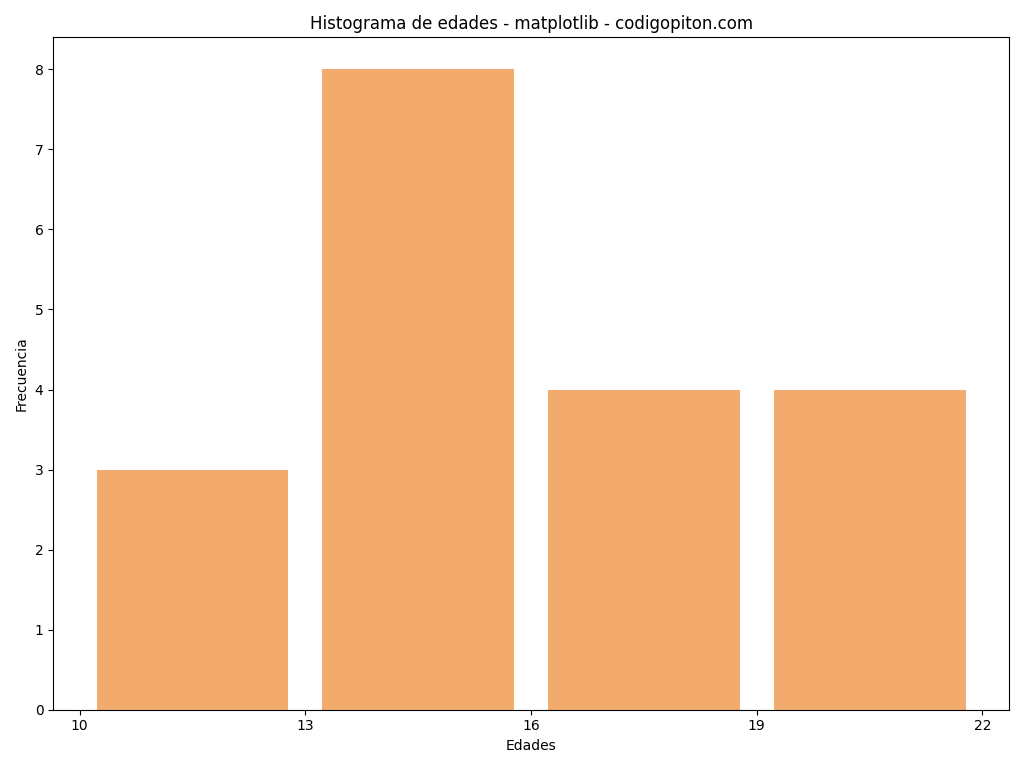
Pasemos a ver cómo generar histogramas con esta misma librería pero utilizando además la librería Pandas.
Histograma con Pandas y Matplotlib
Pandas no es una librería de visualización en sí, sino que se trata de una potente y flexible librería para análisis y manipulación de datos muy utilizada en la actualidad.
Si estás realizando tu proyecto con Pandas y necesitas crear un histograma, aquí tienes la manera de hacerlo junto a Matplotlib.
Necesitamos para ello utilizar la clase Series de Pandas. Esta clase nos permite representar una lista con etiquetas, lo que resulta muy conveniente para el manejo de datos.
En el siguiente ejemplo te muestro como puedes, a partir de un objeto de la clase Series con un conjunto de datos generar un histograma:
import matplotlib.pyplot as plot
import pandas as pd
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
datos = pd.Series(edades) # cargamos los datos en un objeto Series
intervalos = range(min(datos), max(datos) + 2) # calculamos los extremos de los intervalos
datos.plot.hist(bins=8, color='#F2AB6D', rwidth=0.85) # generamos el histograma a partir de los datos
plot.xticks(intervalos)
plot.ylabel('Frecuencia')
plot.xlabel('Edades')
plot.title('Histograma de edades - pandas - codigopiton.com')
plot.show()El código anterior genera un histograma con el mismo aspecto que el caso anterior, pues Pandas no preconfigura el estilo del gráfico de ninguna manera.
De la misma manera que el caso anterior, podemos definir los extremos de intervalos que necesitemos.
Histograma con Seaborn
Pasemos ahora a ver otra librería. Esta vez el turno de Seaborn. Esta librería está construida sobre Matplotlib y proporciona una abstracción de más alto nivel, de forma que permite dibujar gráficos de manera más sencilla todavía. Además, proporciona unos estilos visualmente más atractivos que los estilos por defecto de Matplotlib.
Para hacer un histograma con Seaborn hay que usar la función distplot, a la que hay que proporcionar el conjunto de datos y los intervalos deseados. Después se termina de configurar el gráfico si es necesario y se invoca la función show de Matplotlib para obtener el histograma.
En este caso, como acabo de decir, usaremos la función displot que permite generar diversos gráficos relacionados con la distribución de datos. Por defecto esta función construye un histograma.
Al igual que en los casos anteriores, basta con proporcionar los datos y los extremos de los intervalos. Además, mediante el parámetro color cambiaremos el color de las barras. Otro parámetro, kde, nos permite dibujar sobre el histograma el kernel density estimate de manera muy sencilla (basta con ignorar ese parámetro si no queremos dibujar dicha curva). Finalmente, configuramos el gráfico con las funciones ya conocidas de Matplotlib y listo, lo tenemos.
import matplotlib.pyplot as plot
import seaborn as sb
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
intervalos = range(min(edades), max(edades) + 2)
sb.displot(edades, color='#F2AB6D', bins=intervalos, kde=True) #creamos el gráfico en Seaborn
#configuramos en Matplotlib
plot.xticks(rangos)
plot.ylabel('Frecuencia')
plot.xlabel('Edades')
plot.title('Histograma de edades - Seaborn - codigopiton.com')
plot.show()El resultado es el siguiente y, como ves, esta vez sí que cambia un poco el aspecto general. Si además necesitas modificar los intervalos, ya sabes cómo hacerlo, simplemente proporciona en el parámetro bins una lista con los extremos de los intervalos que necesites.
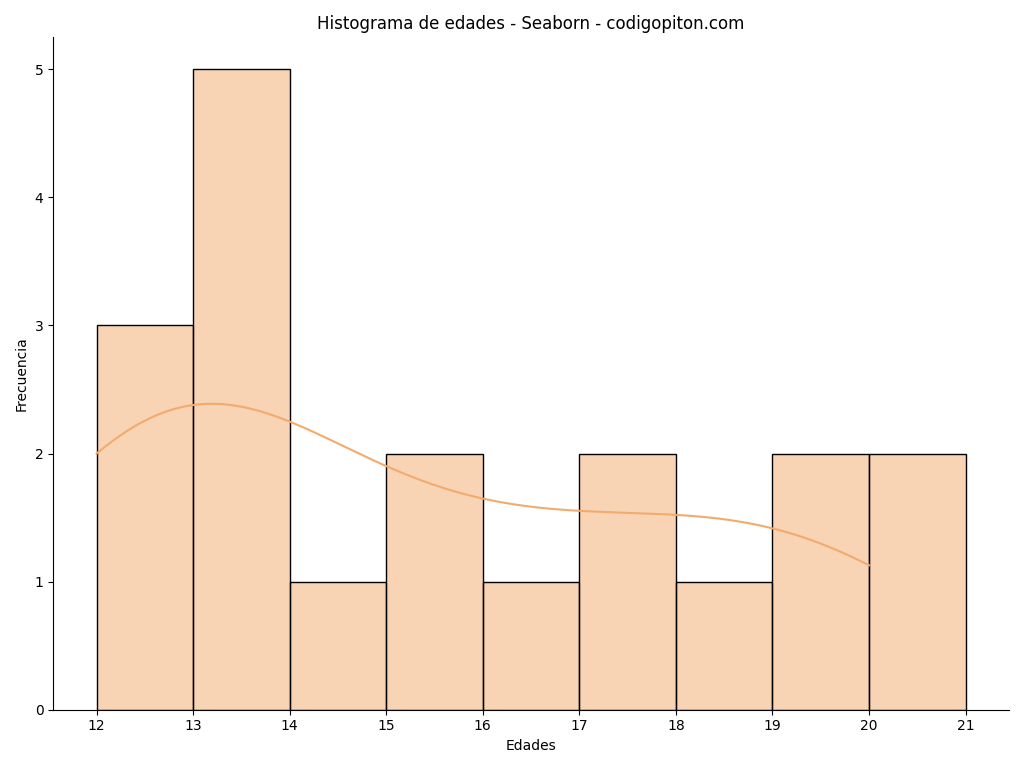
Histograma con Bokeh
Ahora cambiamos un poco y nos alejamos de Matplotlib. Bokeh es una librería de visualización de gráficos interactivos compatible con navegadores web, es decir, que podrás ver los gráficos generados e interactuar con ellos desde un navegador.
Para generar un histograma con Bokeh, primero hay que calcular las frecuencias, manualmente o con numpy, de cada intervalo deseado. Después se utiliza la función figure, que permite crear un gráfico y la función quad para crear cada una de las barras a representar.
Bokeh no dispone de una gráfico específico para los histogramas, por eso tenemos que calcular antes previamente las frecuencias tras determinar los intervalos.
Día que estás fuera, consejo sobre Python que te pierdes.
Antes de suscribirte consulta aquí la
Finalidad de recogida y tratamiento de datos personales: enviarte boletín informativo de Python y comunicaciones comerciales.
Legitimación: tu consentimiento.
Destinatarios: no se ceden a terceros. Los datos se almacenan en los servidores de marketing (GetResponse).
Derechos: podrás ejercer tus derechos de acceso, rectificación, limitación y supresión de datos en info @ codigopiton.com así como presentar una reclamación ante una autoridad de control.
Más información: política de privacidad, encontrarás información adicional sobre la recopilación y el uso de tu información personal.
A continuación definimos un gráfico con la función figure al que añadiremos varios rectángulos con la función quad. Cada uno de esos rectángulos representará una barra en nuestro histograma.
Como ves, a causa de no tener una función específica para histogramas, el proceso es un poco más manual, pero el resultado es muy satisfactorio y la manera de realizarlo es muy sencilla en sí. Veamos el código:
from bokeh.plotting import figure
from bokeh.io import show
import numpy as np
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
rangos = range(min(edades), max(edades) + 2)
frecuencias, bordes = np.histogram(edades, bins=rangos)
# creamos la figura
histograma = figure(title='Histograma de edades - Bokeh - codigopiton.com',
x_axis_label='Edades',
y_axis_label='Frecuencia')
# añadimos las subdiviones al eje X
histograma.xaxis.ticker = bordes
# añadimos los rectángulos que representan las barras del histograma
histograma.quad(bottom=0, top=frecuencias,
left=bordes[:-1], right=bordes[1:],
fill_color='#F2AB6D', line_color='black')
# mostramos el histograma
show(histograma)Lo más importante aquí es, después de haber calculado las frecuencias, proporcionar la información de las coordenadas de los rectángulos que forman cada barra a la función quad. Utilizando los parámetros bottom, top, right y left, y proporcionando sendas listas con las coordenadas correspondientes a los bordes inferior y superior (en el eje Y) y a los bordes derecho e izquierdo (en el eje X) indicamos cada uno de esos rectángulos. Las listas tendrán que tener tantos elementos como rectángulos. En el caso del parámetro bottom, para indicar la coordenada inferior, solo necesitamos indicar el valor 0 ya que todos los rectángulos tendrán esa coordenada inferior.
Respecto de la configuración del gráfico, la función figure tiene diversos parámetros. Los que usamos aquí sirven para indicar un título (title) y las etiquetas de los ejes (x_axis_label e y_axis_label). Para configurar la división del eje X puedes utilizar el atributo xaxis.ticker de la figura proporcionándole una lista de los bordes de los intervalos.
Finalmente, para indicar el color de las barras y su borde exterior, puedes usar los parámetros fill_color (color de relleno) y line_color (color de la línea).
El resultado será el siguiente histograma mostrado en el navegador web del sistema.
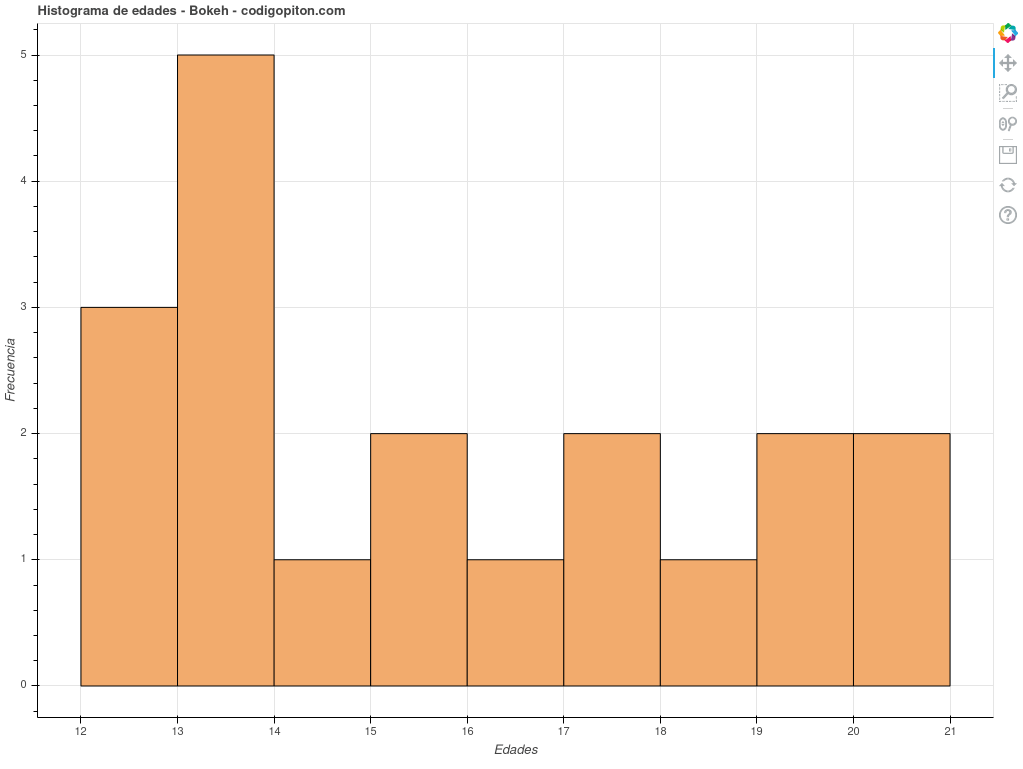
Como te decía, el histograma es interactivo y podrás hacer zoom o desplazarlo, entre otras cosas, si lo necesitas. Además, en la esquina superior derecha, como puedes ver, tienes varias herramientas para trabajar con él.
Histograma con Plotly
Plotly es otra gran librería para la realización de gráficos interactivos, como el caso anterior y que se visualizan en un navegador web.
Para hacer un histograma en Plotly hay dos alternativas principales. Una es el uso del módulo express, que permite realizar un histograma de manera rápida con solo proporcionar los valores y los intervalos. Si hace falta algo más de control se puede usar la clase Figure del módulo graph_objects.
El módulo express de Plotly es un interfaz de alto nivel y de más fácil uso del núclo de Plotly. Con él podemos hacer gráficos de una manera sencilla y rápida, a costa de perder determinadas opciones de configuración o de la posibilidad de hacer gráficos complejos.
En este caso utilizamos la función histogram del módulo express. Solo tienes que proporcionarle la lista con los valores, el número de intervalos a utilizar (parámetro nbins), el título del gráfico (parámetro title) y la secuencia de colores que, cíclicamente, irán tomando las barras del gráfico (parámetro color_discrete_sequence) que, en este caso, solo tendrá un color.
Aunque la función histogram proporciona una parámetro llamado labels que permite modificar las etiquetas de los ejes, sólo he logrado cambiar la del eje X mientras que la del eje Y siempre es "count" (que es la función que se utiliza para el cálculo del histograma, es decir, contar los valores). Para evitar este pequeño inconveniente utilizo la función update_layout que permite modificar varios aspectos, entre ellos, dichas etiquetas. Así, mediante los parámetros xaxis_title e yaxis_title, podemos proporcionar las etiquetas deseadas para ambos ejes.
Veamos el código:
import plotly.express as px
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
numero_intervalos = max(edades) - min(edades) + 1
histograma = px.histogram(edades,
nbins=numero_intervalos,
title='Histograma de edades - Plotly - codigopiton.com',
color_discrete_sequence=['#F2AB6D'])
# configuramos las etiquetas de los ejes
histograma.update_layout(
xaxis_title="Edades",
yaxis_title="Frecuencia"
)
histograma.show()Finalmente, con la función show mostramos el gráfico, que se abre en el navegador web por defecto del sistema y cuyo resultado se puede ver en la imagen a continuación.
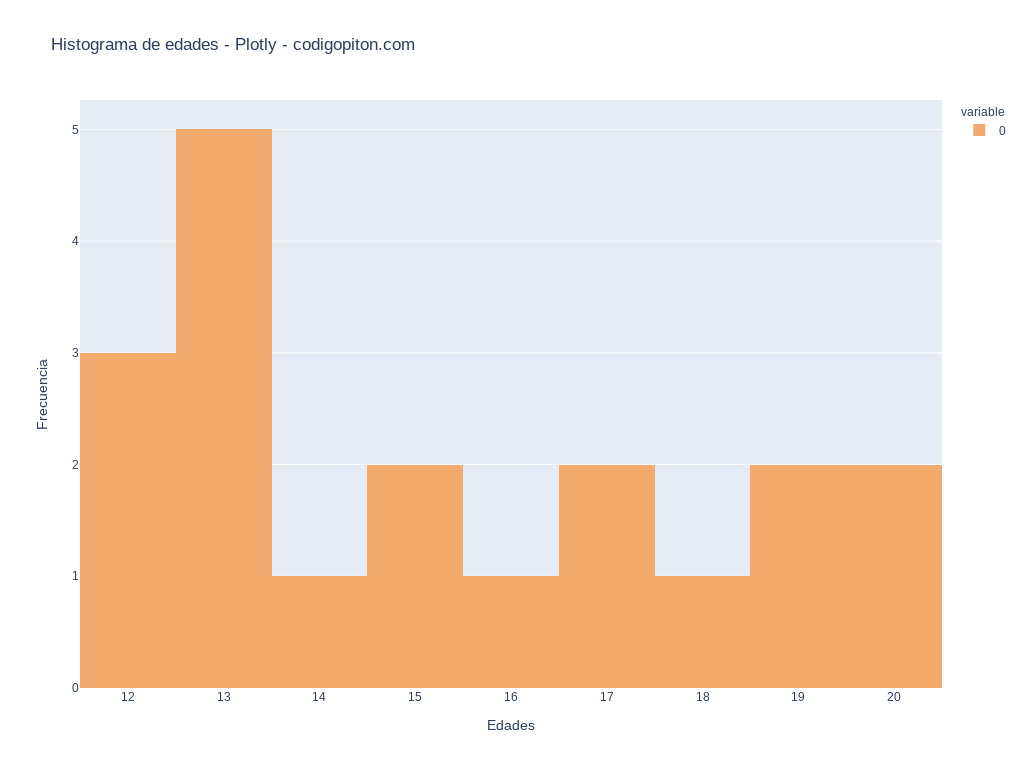
Otra manera de generar histogramas con Plotly, y ya al margen del módulo express, es mediante el uso del núcleo de la librería, concretamente, del módulo graph_objects y de su clase Histogram.
Al construir un objeto de clase Histogram, debemos proporcionar la lista de valores (parámetro x), el número de intervales (parámetro nbinsx) y, opcionalmente, el color de las barras (parámetro marker).
A continuación debemos de crear una figura mediante la clase Figure y a la que proporcionamos, el histograma generado mediante el parámetro data.
Después configuramos el gráfico con la función update_layout como en el caso anterior, pero esta vez le indicamos, además, el título del gráfico (parámetro title).
Finalmente llamaremos a show y se generará un gráfico exactamente igual que el de la imagen anterior. Este es el código:
import plotly.graph_objects as go
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
numero_intervalos = max(edades) - min(edades) + 1
histograma = go.Histogram(x=edades, nbinsx=numero_intervalos, marker={'color': '#F2AB6D'})
figura = go.Figure(data=histograma)
figura.update_layout(
title='Histograma de edades - Plotly - codigopiton.com',
xaxis_title="Edades",
yaxis_title="Frecuencia"
)
figura.show()Si te fijas, y al contrario que sus alternativas, a Plotly no se le indican los bordes de los intervalos, sino el número de intervalos. No he encontrado la manera de poder determinar intervalos de tamaños diferentes. La forma más sencilla de evitar esto es generando un gráfico de barras en lugar de un histograma mediante el uso de la clase Bar. Así la solución sería similar a la manera de hacer histogramas que sugieren Bokeh o pygal, calculando de manera manual las coordenadas de cada una de las barras.
Histograma con Altair
Altair es una librería que trabaja sobre una lenguaje de alto nivel para la realización de gráficos interactivos llamado Vega-Lite.
Para crear un histograma con Altair deben definirse los intervalos con la clase BinParams y crear un gráfico con la clase Chart. Se indica que el gráfico es de barras con la función mark_bar y se trasladan los intervalos al eje X y la función de contar al eje Y, que representará la frecuencia.
A priori, la manera de trabajar de Altair puede parecer menos intuitiva que el resto de alternativas presentadas en este artículo. Eso es debido al lenguaje Vega-Lite que se utiliza en esta librería, que sería interesante aprender para poder usarla con soltura.
Aunque Altair permite recibir los datos a representar en varios formatos, lo más cómodo aquí es encapsularos en un DataFrame de Pandas.
Una vez hecho esto, tienes que definir los intervalos. Para ello hay que utilizar la clase BinParams. Crearemos un objeto y proporcionaremos al constructor, mediante el parámetro extent, el borde inferior y el superior de nuestro conjunto de datos.
Después creamos el gráfico, que será un objeto de la clase Chart. En el constructor indicaremos nuestro conjunto de datos y el título del gráfico (parámetro title). Invocaremos a la función mark_bar del objeto creado para indicar que el gráfico será de barras y después llamaremos a la función encode que se encargará de definir qué barras van a dibujarse.
A la función encode le vamos a proporcionar dos parámetros:
- Parámetro
x, que será un objeto de claseX, al que indicamos la etiqueta asociada con nuestroDataFramede datos, los intervalos definidos (parámetrobin) y la etiqueta del eje X (parámetrotitle). - Parámetro
y, que será un objeto de la claseY. A este objeto le indicamos la función a aplicar a los datos etiquetados según la etiqueta indicada en el objeto de claseX, que será "count()", pues queremos contar los valores dentro de cada intervalo. También indicamos la etiqueta del eje Y.
Finalmente solo queda, y si queremos, aplicar alguna configuración visual, como en este caso hacemos para cambiar el color mediante la función configure_mark y su parámetro color.
Altair viene preparado para funcionar en entornos notebook tipo JupyterLab o Zeppelin. De esta manera, con solo escribir el nombre del objeto histograma creado y configurado en la consola del notebook ya obtendremos el dibujo. Si no quieres utilizar este tipo de entornos, una posible manera de obtener el dibujo pasa por instalar la librería altair_view y, una vez creado el objeto, invocar a su función show, lo que hará que se abra el navegador web por defecto del sistema con el gráfico deseado.
A continuación te muestro el código, en donde se utiliza la mencionada función show:
import altair as alt
import pandas as pd
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
datos = pd.DataFrame({'edad': edades})
intervalos = alt.BinParams(extent=[min(edades), max(edades) + 1])
histograma = alt.Chart(datos, title='Histograma de edades - Altair - codigopiton.com') \
.mark_bar().encode(
x=alt.X('edad', bin=intervalos, title='edades'),
y=alt.Y('count()', title='frecuencia')).configure_mark(color='#F2AB6D')
histograma.show()El código anterior genera el siguiente gráfico:
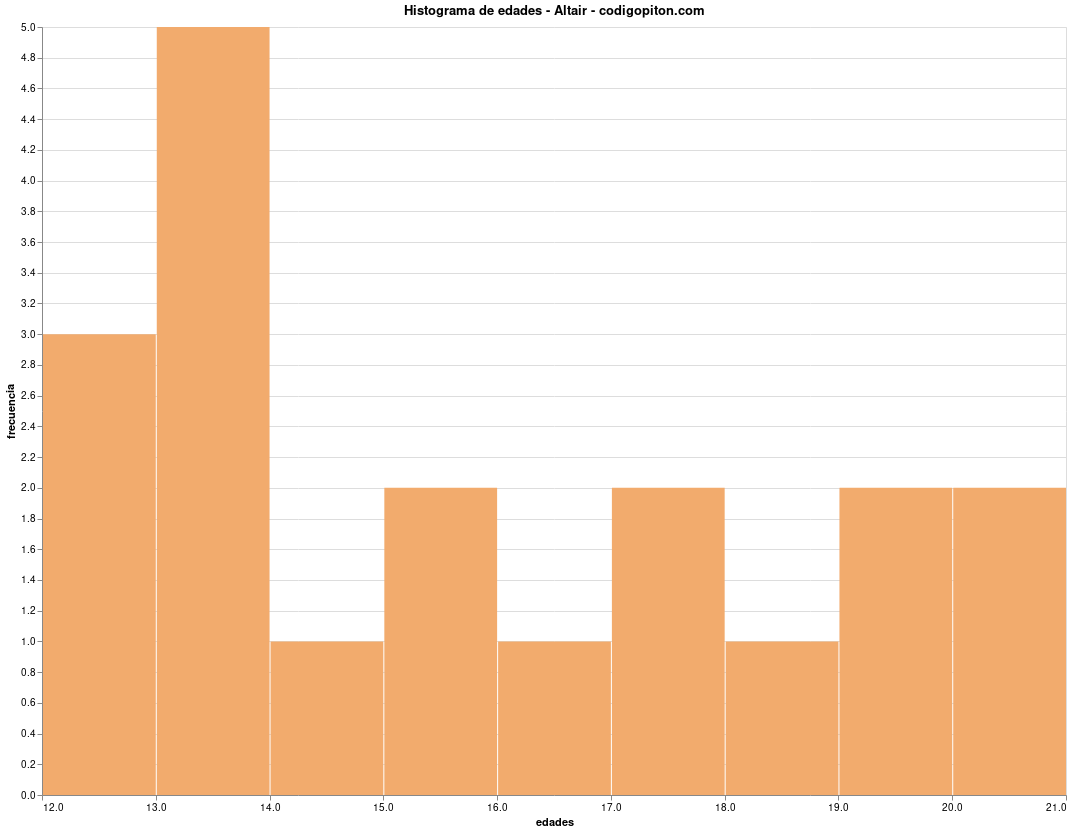
Aunque es muy sencillo configurar la anchura de cada intervalo utilizando los parámetros step, steps o divide, nos sucede como en el caso anterior. No he encontrado en la documentación de Altair la manera de definir anchuras arbitrarias a nuestro gusto, así que aquí, de nuevo, habría que realizar el gráfico de otra manera.
Histograma con pygal
Y, finalmente, te presento a pygal, otra librería que permite la creación de gráficos interactivos.
Para hacer un histograma con pygal hay que crea una lista de tuplas con tres valores: la frecuencia, el borde izquierdo y el borde derecho de cada intervalo. Después se crea un objeto de la clase Histogram y se le proporciona la lista de tuplas creada mediante la función add.
Nuevamente nos encontramos con un caso en el que debemos de calcular nosotros la frecuencias, y no solo eso, sino que además tendremos crear una lista con varios elementos, uno para cada intervalo. Así, para cada uno de ellos crearemos una tupla con tres valores. El primero será la frecuencia calculada, que podemos calcular usando NumPy como ya te he explicado más arriba. El segundo y tercer valores serán los bordes izquierdo y derecho de ese intervalo.
Una vez tenemos esa lista, la manera de crear el histograma es muy sencilla. Usaremos la clase Histogram de la que crearemos un objeto. En el constructor indicaremos un título para el gráfico (parámetro title) y etiquetas para los ejes X e Y (parámetros x_title e y_title, respectivamente). De manera opcional podemos indicar un estilo para el gráfico usando el parámetro style.
En este caso también queremos cambiar el color de las barras como hemos hecho en los ejemplos del resto de librerías. Para ello creamos un objeto de la clase Style y mediante el parámetro colors indicamos una lista de colores con un único color.
Tras haber creado el objeto Histogram solo nos resta indicarle cuáles son los datos a representar. Para eso usamos el método add indicando un nombre para la variable y la lista de tuplas que hemos calculado previamente.
Y con esto, y si estamos en un entorno notebook tipo JupyterLab, basta con escribir el nombre del objeto Histogram para obtener el dibujo. Si no, y si tenemos instalada la librería lxml, podemos usar el método render_in_browser para obtener el gráfico en el programa que tengamos asociado con gráficos SVG, pues este es el formato por defecto que genera la librería.
A continuación te muestro el código de ejemplo así como la imagen de su resultado:
from pygal import Histogram
from pygal.style import Style
import numpy as np
edades = [12, 15, 13, 12, 18, 20, 19, 20, 13, 12, 13, 17, 15, 16, 13, 14, 13, 17, 19]
intervalos = range(min(edades), max(edades) + 2)
frecuencias, bordes = np.histogram(edades, bins=intervalos) # calculamos las frecuencias con NumPy
datos = []
# generamos la lista de tuplas con la información de cada intervalo
for i, valor in enumerate(frecuencias):
datos.append((valor, intervalos[i], intervalos[i + 1]))
estilo = Style(colors=['#F2AB6D']) # creamos un estilo para darle color a las barras
# creamos el histograma y añadimos los datos
histograma = Histogram(title='Histograma de edades - pygal - codigopiton.com',
x_title='edades', y_title='frecuencias', style=estilo)
histograma.add('Edades', datos)
histograma.render_in_browser()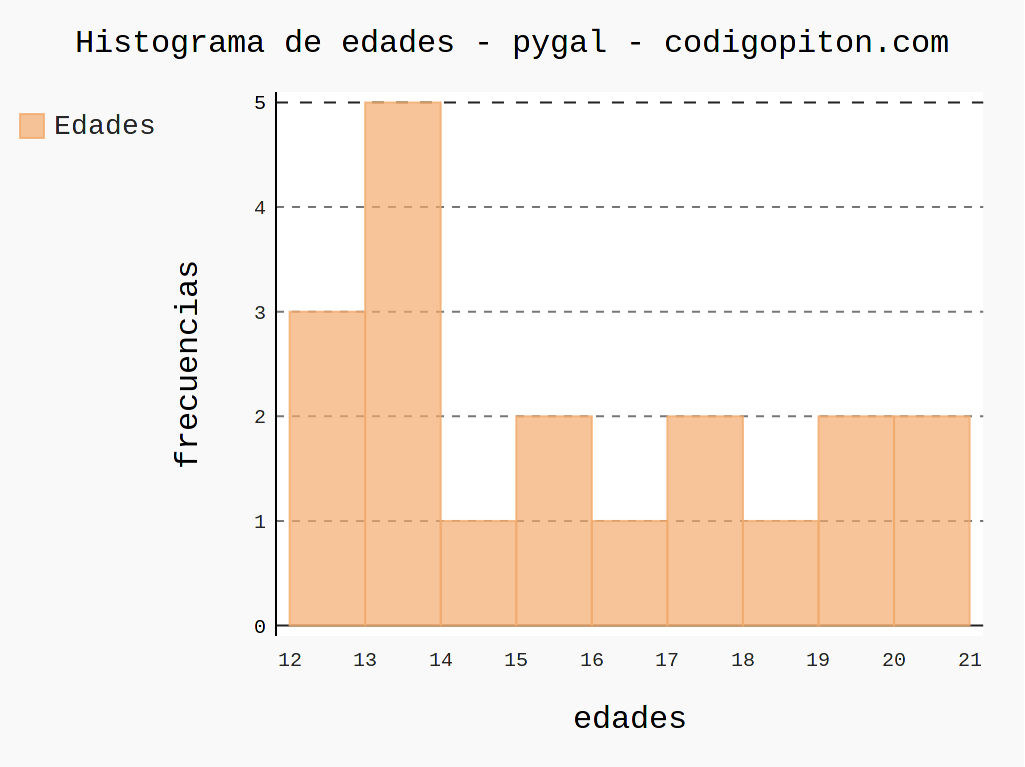
Ejemplo con datos reales
Bueno, ya te he presentado unas cuantas alternativas, pero lo he hecho con datos ficticios de forma que los gráficos generados eran un tanto simples. Veamos aquí un caso real donde utilicemos datos de verdad y de manera que tengamos que leerlos de un fichero.
Voy a hacer dos versiones de este mismo ejemplo. La primera será con Matplotlib porque sigue siendo, a día de escribir este artículo, la librería de visualización más utilizada en Python. La segunda opción elegida será Plotly, pues es una librería más moderna y con capacidad, como ya he dicho, de generar gráficos interactivos.
El problema: número de vuelos del año 2019
Los datos a utilizar están extraídos de Flightradar 24, un servicio de seguimiento de vuelos global. El fichero con los datos, que puedes descagar en este enlace, es un fichero de datos separados por comas (CSV) con 366 líneas. La primera contiene la cabecera que indica los nombres de las columnas, que son "Fecha" y "Vuelos". A continuación, 365 líneas más, donde cada una de ellas contiene la fecha de un día del año 2019 y el número de vuelos total a nivel mundial de ese día. Todos los valores están separados por un punto y coma. Las primeras filas del fichero tienen este aspecto:
Fecha;Vuelos
2019-01-01;128717
2019-01-02;162303
2019-01-03;169310
2019-01-04;173386
2019-01-05;161288
2019-01-06;156172
2019-01-07;163601
2019-01-08;163535
2019-01-09;167080
...El problema se trata de leer los datos del fichero y realizar un histograma en el que se pueda ver la distribución del número de vuelos por días. Es decir, en el eje X del histograma tendremos representados los intervalos del número de vuelos, y en el eje Y el número de días con un número de vuelos incluido en dichos intervalos.
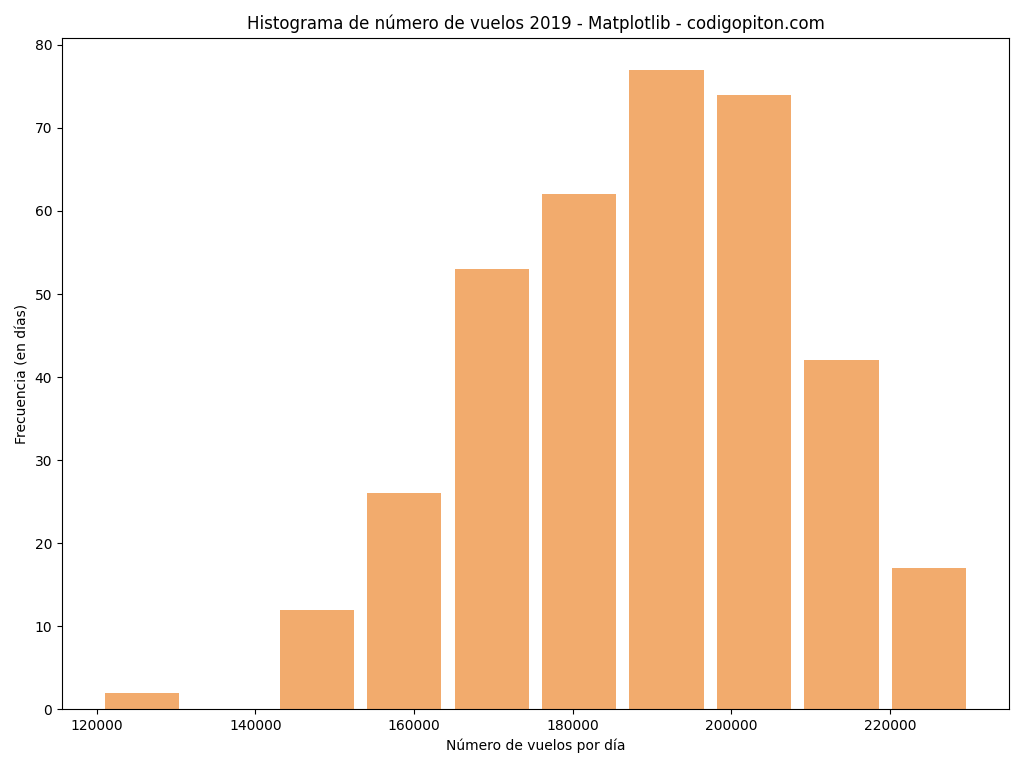
Resolviendo con Matplotlib
Tanto como para esta como para la segunda versión, la lectura de datos se realiza de la misma manera utilizando el módulo csv.
En esta ocasión no indicamos los intervalos a usar y dejamos que matplotlib los elija por nosotros. Puedes comprobar que, una vez leídos los datos, el proceso es muy similar al ya presentado.
El código queda como sigue:
import csv # importamos csv para poder leer el fichero de entrada
import matplotlib.pyplot as plot
# leemos el fichero de datos
nombre_fichero = 'numero-de-vuelos-por-dia-2019.csv'
with open(nombre_fichero) as fichero:
lector = csv.DictReader(fichero, delimiter=';')
vuelos = [int(fila['Vuelos']) for fila in lector] # cargamos la lista del número de vuelos
# creamos el histograma
plot.hist(x=vuelos, color='#F2AB6D', rwidth=0.85)
# configuramos
plot.xlabel('Número de vuelos por día')
plot.ylabel('Frecuencia (en días)')
plot.title('Histograma de número de vuelos 2019 - Matplotlib - codigopiton.com')
# dibujamos
plot.show()Así, la imagen con el resultado es la siguiente:
Resolviendo con Plotly
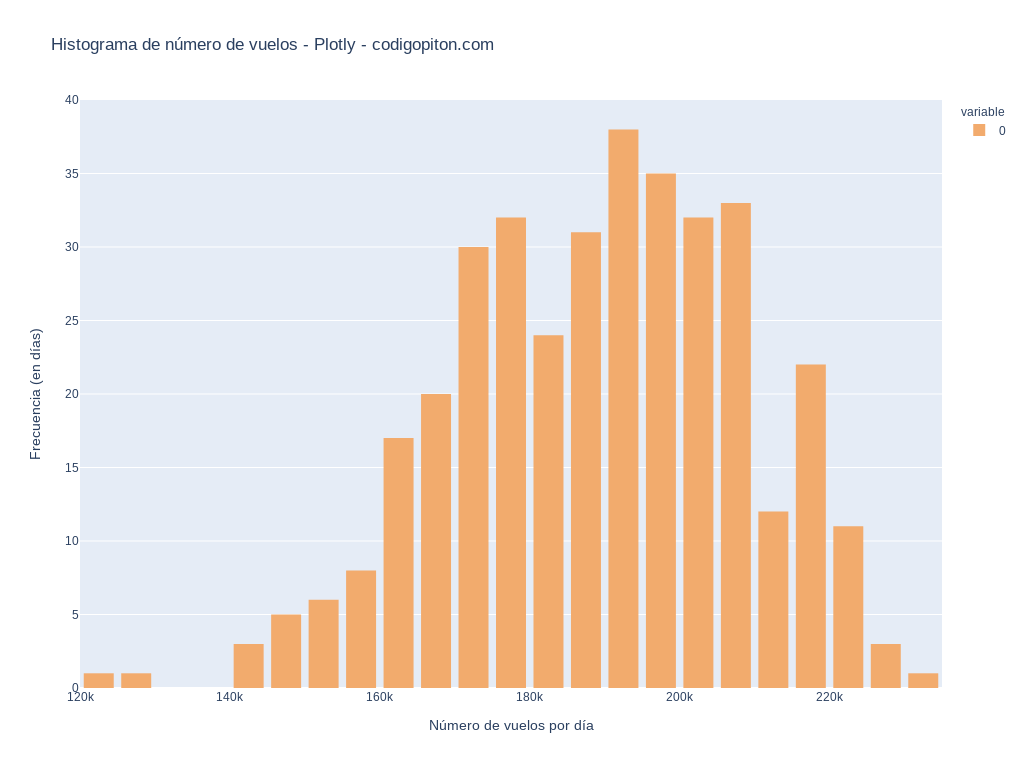
Como ya dije, la manera de leer los datos en este segundo ejemplo no varía en absoluto. Solo cambiamos la manera en que se genera el gráfico.
Nuevamente, vamos a dejar que Plotly seleccione los intervalos por nosotros. Cuando los datos se leen, el proceso de dibujar el histograma es similar al presentado previamente:
import csv
import plotly.express as px
# leemos el fichero de datos
nombre_fichero = 'numero-de-vuelos-por-dia-2019.csv'
with open(nombre_fichero) as fichero:
lector = csv.DictReader(fichero, delimiter=';')
vuelos = [int(fila['Vuelos']) for fila in lector]
#creamos el histograma
histograma = px.histogram(vuelos,
title='Histograma de número de vuelos - Plotly - codigopiton.com',
color_discrete_sequence=['#F2AB6D'])
# configuramos las etiquetas de los ejes y la distancia entre barras
histograma.update_layout(
xaxis_title="Número de vuelos por día",
yaxis_title="Frecuencia (en días)",
bargap=0.2
)
#dibujamos
histograma.show()Y el resultado lo puedes ver en la imagen a continuación. Si te fijas, varía respecto del caso anterior porque el número de intervalos es diferente.
Problema extra: mostrar el número de vuelos por mes con Panda
Y antes de ir terminando este artículo (que ya va tocando), te propongo y resuelvo un ejercicio extra. La idea es representar el número de vuelos por mes. Podemos pensar este gráfico como un gráfico de barras normal aunque en cierta forma es un histograma, pues se trata de representar una distribución de los datos agrupando por mes y no por el valor de los datos.
Vamos a utilizar en esta ocasión una óptica diferente. Los datos ya vienen agrupados por días, así que tendremos que leerlos y agruparlos por mes. Para realizar esta operación vamos a utilizar Pandas, ya que así podremos manipular los datos de manera sencilla y conveniente.
Pandas nos permite leer directamente los datos del fichero CSV de manera muy cómoda. Además, ya se genera un DataFrame con los datos del fichero.
Antes de poder proceder con la agrupación de datos por mes, necesitamos extraer el valor del mes del campo "Fecha". Para eso añadimos una nueva columna al DataFrame extrayendo el mes de la fecha por medio de la función split.
Ahora que tenemos una nueva columa en el DataFrame ya podemos realizar el agrupamiento. Utilizamos la función groupby para agrupar por el campo "Mes" y a continuación sumamos los valores del campo "Vuelos" para cada grupo.
Solo resta dibujar un gráfico de barras con el número de vuelos para cada mes. Utilizamos para ello la función plot a la que proporcionamos el tipo de gráfico bar (parámetro kind) así como otros valores de configuración como el color de las barras, el título del gráfico y las etiquetas de los ejes.
El código queda muy compacto gracias a la gran potencia de Pandas:
import pandas as pd
import matplotlib.pyplot as plot
plot.figure(figsize=(10.24, 7.68))
# obtenemos un DataFrame con los datos del fichero
nombre_fichero = 'numero-de-vuelos-por-dia-2019.csv'
vuelos = pd.read_csv(nombre_fichero, sep=';')
# creamos una nueva columna con el campo mes por el que queremos agregar
vuelos['Mes'] = vuelos['Fecha'].map(lambda fecha: fecha.split('-')[1])
# agrupamos por mes y sumamos la columna de vuelos
# después dibujamos un gráfico de barras
vuelos.groupby('Mes')['Vuelos'].sum().plot(kind='bar',
color='#F2AB6D',
title='Número de vuelos mensuales 2019 - Pandas - codigopiton.com',
ylabel='Número de vuelos')
plot.show()Finalmente, tras la llamada a la función show obtendremos el siguiente resultado:
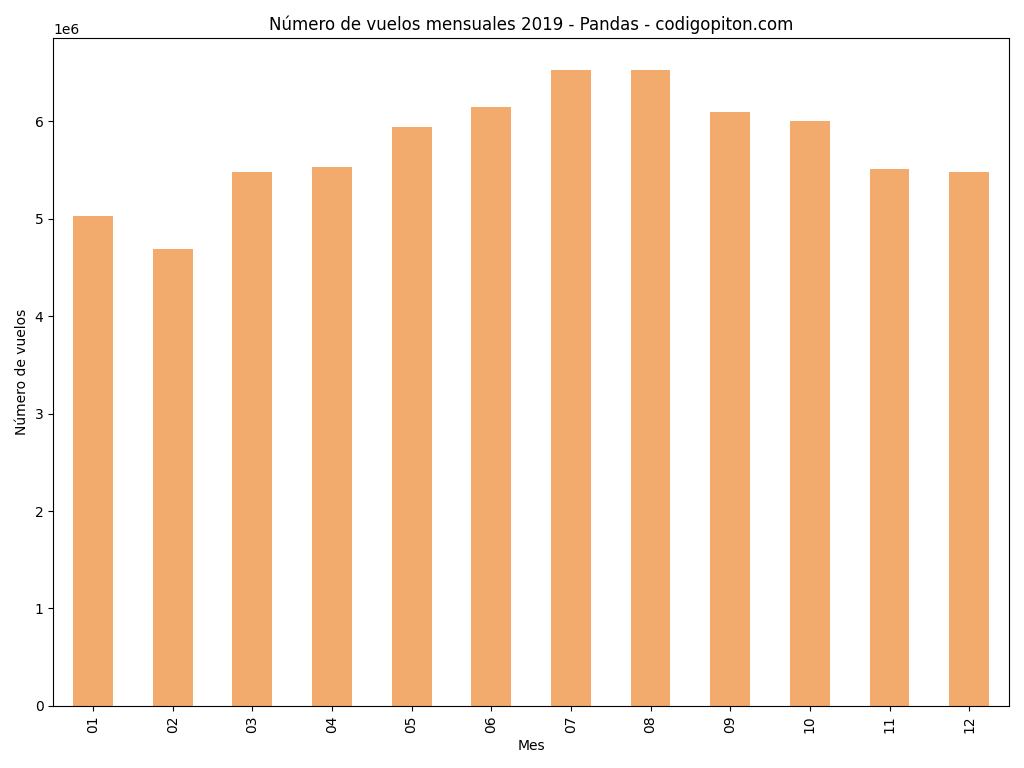
Conclusión: ¿qué método debo elegir?
Bueno, creo que me ha quedado una entrada un poco larga. Espero que haya valido la pena y puedas sacar provecho de ella, pues he invertido muchas horas.
Aquí has aprendido cómo realizar un histograma, haciendo los cálculos a mano, utilizando la clase Counter o la librería NumPy. Además has visto como poder representar un histograma textualmente o utilizando algunas de las librerías de visualización de datos más usadas y potentes. También hemos trabajando con la librería Pandas, que nos permite dibujar gráficos y manipular los datos de manera sencilla.
¿Qué te toca ahora? Pues tendrás que elegir cuál es el método que mejor te viene. Eso lo tendrás que decidir tú, pues solo tú conoces la naturaleza de tu problema y sus requisitos. De todas formas te voy a dar una pequeña guía para que no te vayas dando tumbos sin saber hacia donde apuntar:
- Si solo necesitas hacer un gráfico sencillo, con pocos datos y nada más, puedes optar por la primera opción y hacer una representación textual. Si necesitas algo más profesional, para un trabajo, un artículo o un libro, opta por cualquier de las librerías aquí explicadas.
- Si quieres acogerte a lo que se considera más estándar, una buena opción es Matplotlib.
- Si quieres gráficos que sean más bonitos que lo que ofrece Matplotlib por defecto, pásate a Seaborn.
- Si no necesitas gráficos interactivos elige Matplotlib o Seaborn (aunque se pueden llegar a hacer).
- Si quieres gráficos interactivos elige Plotly, Altair, Bokeh o pygal.
Ten en cuenta también, para tu decisión, si necesitas utilizar NumPy o Pandas y su nivel de integración con cada librería.
En cualquier caso, te diré que yo últimamente he utilizado Plotly y que también me inclino por Seaborn.
Mi recomendación final: prueba dos o tres librerías y elige la que te resulte más cómoda o natural y se adapte más a tu estilo y manera de trabajar.
¡Suerte con tus histogramas!
Te envío todos los días un consejo para que cada día seas mejor en Python.
Siempre sobre Python y programación.
Más de 2500 personas como tú los reciben cada día.
Día que estás fuera, consejo sobre Python que te pierdes.
Antes de suscribirte consulta aquí la
Finalidad de recogida y tratamiento de datos personales: enviarte boletín informativo de Python y comunicaciones comerciales.
Legitimación: tu consentimiento.
Destinatarios: no se ceden a terceros. Los datos se almacenan en los servidores de marketing (GetResponse).
Derechos: podrás ejercer tus derechos de acceso, rectificación, limitación y supresión de datos en info @ codigopiton.com así como presentar una reclamación ante una autoridad de control.
Más información: política de privacidad, encontrarás información adicional sobre la recopilación y el uso de tu información personal.